Thanks for getting the flight recordings up. This is a pretty interesting scenario, but I'm afraid I can't give conclusive answers, mostly because for some reason
- The information in your flight recordings is weirdly incomplete. I'll explain a little more shortly
- There seems to be other things going on in your system that may be muddying the diagnosis. You might benefit from killing any other running process in your machine.
So, what now/(TL;DR)
- You need to be sure that your connection source to the database is pooled
- Make sure you start your load test on a calm, clear-headed CPU
- Configure your next flight recording to take sufficient, intermittent thread dumps. This is probably the most important next step, if you're interested in figuring out what exactly all these threads are waiting for. Don't post up another flight recording until you're positive it contains multiple thread dumps that feature all the live threads in your JVM.
- Maybe 10k threads isn't reasonable for your local machine
- I also noticed from the flight recording that you have a heap size maxed at 7GB. If you're not on a 64bit OS, that could actually be harmful. A 32-bit OS can address a max of 4GB.
- Make sure there aren't any actual database failures causing the whole thing to thrash. Are you running out of connections? Are there any SQLExceptions blowing up somewhere? Any exceptions at all?
Here's what I could tell from your recordings:
CPU
Both flight recordings show that your CPU was struggling for good chunks of both of your recordings:
The MSSQL recording (46 mins total)
JFR even warns in the MSSQL recording that:
An average CPU load of 42 % was caused by other processes during 1 min 17 s starting at 2/18/21 7:28:58 AM.
The H2 recording (20.3s total)
I noticed that your flight recordings are titled XXXX_10000. If this means "10k concurrent requests", it may simply mean that your machine simply can't deal with the load you're putting on it. You may also benefit from first ensuring that your cores don't have a bunch of other things hogging their time before you kick off another test. At any rate, hitting 100% CPU utilization is bound to cause lock contention as a matter of course, due to context switching. Your flight recording shows that you're running on an 8-core machine; but you noted that you're running a dockerized MSSQL. How many cores did you allocate to Docker?
Blocked Threads
There's a tonne of blocking in your setup, and there are smoking guns everywhere. The thread identified by Log4j2-TF-1-AsyncLoggerConfig-1 was blocked a lot by the garbage collector, just as the CPU was thrashing:
The H2 flight recording:
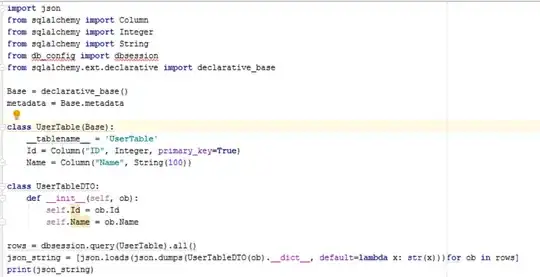
All but the last 3 ticks across that graph were blockings of the log4j2 thread. There was still significant blocking of the other pooled threads by GC (more on that further down)
The MSSQL flight recording had smoother GC, but both flight recordings featured blocking by GC and the consequent super high CPU utilization. One thing was clear from the MSSQL and H2 recording: every other pooled thread was blocked, waiting for a lock on the same object ID
For MSSQL, lock ID: 0x1304EA4F#40; for H2, lock ID: 0x21A1100D7D0
Every thread except the main thread and pool-1-thread-1 (which was blocked by garbage collection) exhibits this behavior.
These 7 threads are all waiting for the same object. There is definitely some blocking or even a deadlock somewhere in your setup.
The small specks of green also corroborate the intermittent transfer of monitor locks between the various threads, confirming that they're sort of deadlocked. The pane that shows the threads at the bottom gives a timeline of each thread's blockage. Red indicates blocked; green indicates running. If you hover over each thread's red portion, it shows you that
- The thread is blocked, waiting to acquire a lock (RED)
- The ID of the lock that the thread is trying to acquire and is currently unable
- The ID of the thread that last held the lock
- Green indicates a running, unblocked thread.
When you hover over the red slices in your flight recording, you'll see that they're all waiting to acquire the same lock. That lock is intermittently held between the various pooled threads.
MSSQL (threads blocked waiting for 0x1304EA4F40):

H2 (threads blocked waiting for 0x21A1100D7D0):
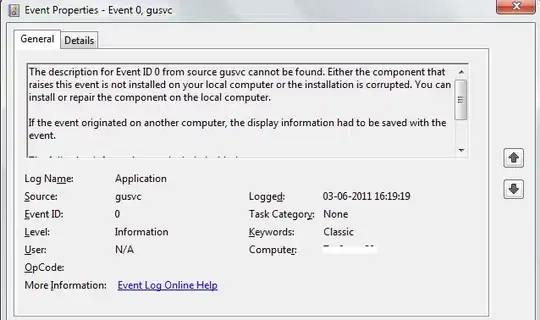
In both flight recordings, pool-1-thread-1 is the sole thread that isn't blocked while trying to acquire a lock. That blank row for pool-1-thread-1 is solely due to garbage collection, which I covered earlier.
Dumps
Ideally, your flight recordings should contain a bunch of thread dumps, especially the one that you ran for over 40 mins; never mind the 20s one. Unfortunately, both recordings contain just 2 recordings each; only one of each of them even contains the stacktrace for pool-1-thread-1. Singular thread dumps are worthless. You'll need multiple snapshots over a length of time to make use of them. With a thread dump (or a heap dump), one could identify what objects the IDs 0x1304EA4F40 and 0x21A1100D7D0 refer to. The most I could figure out from the dumps is that they're all waiting for an instance of "Object":

It literally could be anything. Your very first flight recording at least showed that the threads were locked on org.apache.logging.log4j.core.appender.db.jdbc.JdbcDatabaseManager:
That very first recording shows the same pattern in the locks pane, that all the threads were waiting for that single object:
That first recording also shows us what pool-1-thread-1 was up to at that one instant:
From there, I would hazard a guess that that thread was in the middle of closing a database connection? Nothing conclusive can be said until multiple successive thread dumps show the thread activity over a span of time.









