Data in your current format can be referred to as Interleaved, that is there are multiple distinct types of records however their only relation to each other is by their position in the file. This structure provides an interesting challenge to represent in JSON, which is an object notation aslos referred to as a Graph of hierarchical data.
When converting this data to JSON we should consider what value the structure will add to the final consumer, there is always some value in making the data easier to parse and consume, even if you are not selling the data feed, you can reduce costs if you need to answer less questions about the data later.
The two record types in the set are:
- Index
- Text Entry
Because there is a 1:1 relationship between these records, there is no value in nesting one of these records within the other in the JSON output. There are also no shared/common fields between the two records, neither is there a linking field between the two. This means that each record is dependent on the other.
From the consumer point of view, the index is meaningless on its own, indexes are usually designed to facilitate searching for or referencing a record quickly.
As the task here is to process the data line by line and we've identified there is little value in producing a nested structure and there are no common fields, this interleaved dataset can be easily merged or flattened into a simple array of single records
After analysing the data we might be able to identify ways to normalise it into object graphs but it would require re-processing of the entire file and the overall benefit to the consuming user would be questionable, data is generally easier to consume by a wider array of tools if it is flat, rather than a nested structure.
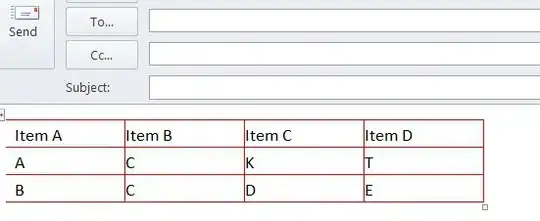
To flatten this data, we take the fields from the index record, and inject them into the text entry, in this example I have also flattened out the index structure that was itself a single nested object:
[
{"index":"tolstoy","_id":27, "type":"line","line_id":100,"book":"War and Peace","speech_number":1,"speaker":"Sonya","text_entry":"Weep. It will do you good"},
{"index":"tolstoy","_id":28, "type":"line","line_id":101,"book":"War and Peace","speech_number":1,"speaker":"Sonya","text_entry":"I will call Pyotr."}
]
See this in json2table.com:
The steps to achieve this:
prefix the file with a new line that starts the array: [
remove {"_index": this is safe to do globally with simple find and replace
join the index and text entry records by replacing the following, including the line break with a comma:
}}
{
if you are using visual studio, this can be achieved with a simple find and replace with a regular expression, the following is just an example to illustrate what is going to be replaced:
- after applying the previous transformations
Now append the whole file with the array close character: ]
Append every line the ends with } with a comma
4. and 5. can be reversed, from an automation point of view I found that as an easier way to ensure that last line did not have a comma
things to consider:
Having flattened the index, I would also suggest changing the name of _id to index_id after reading this post back I'm surprised I missed it the first time.
Overall the names used for fields in this file are intuitive, but if the file itself is quite large (and if that is an issue...), then you could save a few bytes by reducing the names of other fields like text_entry to text, speech_number to speechId/speechNo/speechNum,
When reducing names for data integrations you should try to avoid reducing columns to ambiguous terms like line_id to lid or speech_number to sid as this imposes more assumptions on the consumer, which means more time you need to spend documenting or answering questions.
When optimising data feeds, you need to find a balance between what is theoretically achievable and what is practical with the resources available to both you and the consumer.
- each case will be different, for different reasons.
If every record in the file has the same value for a field, then that field could be removed entirely, in the current example type has the potential to fall into this category.
If bytes across the wire is a concern, and you want to stick with JSON, then normalising the data into a nested object graph is an option, you should use some sort of mapping or translation service to do this, or code, I wouldn't attempt it by hand, but it might look something like nested arrays in this order:
If you were to process this into a normalised structure, it might look something like this:
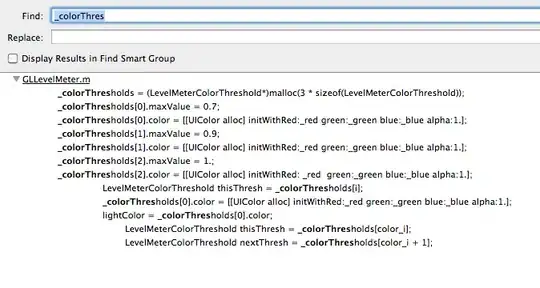
For a large file (with whitespace removed) that could make a significant difference whilst it is still easy to target the nodes in the graph via expression syntax, importantly no information has been lost.


