Fist of all, I've read this SO post, which is very helpful, too; However, to be 100% sure of that the important data will not be mistakenly changed, I want to ask more specific questions.
Some backgrounds:
- My company maintains a running application. It uses mysql and we set the DB on a AWS EC2 instance.
- For some reason I go to check the data in the DB directly. I saw the following by run a SELECT command
- At the cell of 2nd row by column
code1, it shows?????, but it shouldn't be. It should be some Japanese characters. - Below is the output after I run
show variables like 'char%';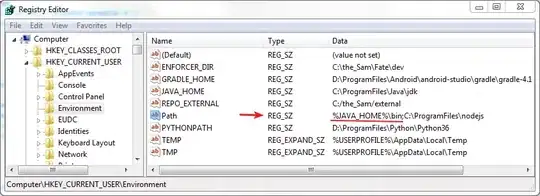
- Another colleague connects to the exactly same EC2 instance and DB. No encoding problem happens. There is no
?????but the correct content. - The output of
show variables like 'char%';, on that end, differs from mine by that there are allutf8, nolatin1. - The system language of my mac is English, and on the other mac is Japanese.


My questions:
Do the mysql variables differ by each host connecting to the EC2 instance? I thought they are variables for the EC2 instance/the DB (so whoever connects to it should see the same values, but apparently it is not the case)
I guess if I change all the variables to
utf8the encoding problem will disappear. But I don't want to try this casually, given the risk of ruining the data. Will this effect the existing data, if run only SELECT command after that? Do I have to change the variables back tolatin1for the sake of data-integrity?Given that this is a running application, even if I don't perform some CREATE or UPDATE commands, what if the end users have made some changed, after I change the mysql encoding variables? Will the new data added by the end user have encoding problem?