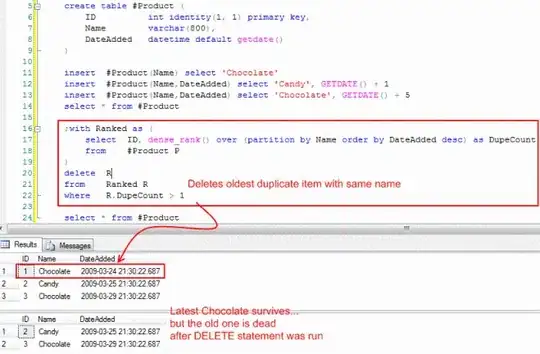
I've got a table that has rows that are unique except for one value in one column (let's call it 'Name'). Another column is 'Date' which is the date it was added to the database.
What I want to do is find the duplicate values in 'Name', and then delete the ones with the oldest dates in 'Date', leaving the most recent one.
Seems like a relatively easy query, but I know very little about SQL apart from simple queries.
Any ideas?