I am working with pair of texts. Some data is redundant for different columns of the data frame.
For example, the screenshot of data frame is following:
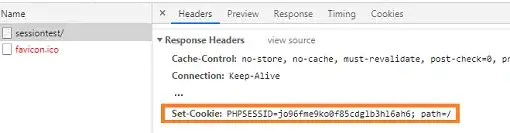
| COLUMN_A | COLUMN_B |
|---|---|
| a | x |
| b | y |
| x | a |
Here row 0 has (a,x) and row 2 has (x,a), which is redundant in my case and has to be deleted. I am building a huge dataset for comparing the semantic similarity between two pairs of texts. At the moment, I want to compare each row with all of the other rows of the same data frame to remove duplicates. How can I compare both columns of each row with all of the other rows?