- The angular position of a pixel
As explained in the article you linked, you can compute the pixel angle by knowing the camera intrinsic parameters. Firstly let's do a bit of theory: the intrinsics matrix is used to compute the projection of a world point in the image plane of the camera. The OpenCV documentation explains it very well, it is expressed like this:
( x ) ( fx 0 cx ) ( X )
s * ( y ) = ( 0 fy cy ) * ( Y )
( 1 ) ( 0 0 1 ) ( Z )
where fx,fy is your focals, cx,cy is the optical centre, x,y is the position of the pixel in your image and X,Y,Z is your world point in meters or millimetres or whatever.
Now by inverting the matrix you can instead compute the world vector from the pixel position. World vector and not world point because the distance d between the camera and the real object is unknown.
( X ) ( x )
d * ( Y ) = A^-1 * ( y )
( Z ) ( 1 )
And then you can simply compute the angle between the optical axis and this world vector to get your phi angle, for example with the formula detailed in this answer using the y-axis of the camera as normal. In pseudo-code:
intrinsic_inv = invert(intrinsic)
world_vector = multiply(intrinsic_inv, (x, y, 1))
optical axis = (0, 0, 1)
normal = (0, 1, 0)
dot = dot_product(world_vector, optical_axis)
det = dot_product(normal, cross_product(world_vector, optical_axis))
phi = atan2(det, dot)
- The camera angles
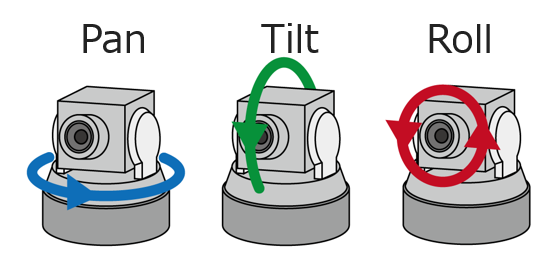
You can express the rotation of the camera by three angles: the tilt, the pan, and the roll angles. Take a look at this image I quickly googled if you want to visualize what they correspond to.
The tilt angle is the one named theta in your article, you already know it. The pan angle doesn't have an impact on the GSD, at least if we suppose that the ground is perfectly flat. If the pan angle was what you were referring to with the second rotation axis, then you'll have nothing to do.
However, if you have a non-zero roll angle this will become tricky. If you are in that case I would recommend a paradigm change to avoid dealing with angles. You can instead express the camera position using an affine transformation (rotation matrix and translation vector). This will allow you to transform the problem into a general analytical geometry problem, and then estimate the depths and scales by doing the intersection of the world vector with the ground plane. It would change the previous pseudo-code to give something like:
intrinsic_inv = invert(intrinsic)
world_vector = multiply(intrinsic_inv, (x, y, 1))
world_vector = multiply(rotation, world_vector) + translation
world_point = intersection(world_vector, ground_plane)
And then the scale can be computed by doing the differences between adjacent pixel world points.



{kind=link}