If you see the difference by checking with df.dtypes it's evident that you r datatype is ultimately is an object but column is only string hence you need to apply pandas.Series.str.replace to get your results.
However, when you choose dtype="object" your both dtype and column data remains object thus you don't need to use .str converion.
Please check the source code, which explains it well:
For calling .str.{method} on a Series or Index, it is necessary to
first
initialize the :class:StringMethods object, and then call the method.
>>> df = pd.DataFrame({'a': ['asdf']}, dtype="string")
>>> df
a
0 asdf
>>> df.dtypes
a string
dtype: object
>>> df["a"].str.replace("a", "b", regex=True)
0 bsdf
Name: a, dtype: string
>>> df = pd.DataFrame({'a': ['asdf']}, dtype="object")
>>> df.dtypes
a object
dtype: object
dtype:
browned from @HYRY.
Look at here source of inspiration for below explanation
From pandas docs where All dtypes can now be converted to StringDtype
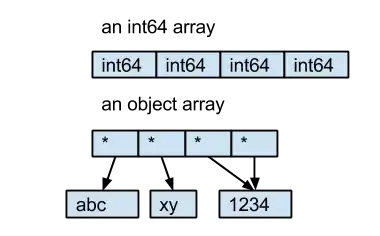
The dtype object comes from NumPy, it describes the type of element in a ndarray. Every element in an ndarray must have the same size in bytes. For int64 and float64, they are 8 bytes. But for strings, the length of the string is not fixed. So instead of saving the bytes of strings in the ndarray directly, Pandas uses an object ndarray, which saves pointers to objects; because of this the dtype of this kind ndarray is object.
Here is an example:
- the int64 array contains 4 int64 value.
- the object array contains 4 pointers to 3 string objects.
Note:
Object dtype have a much broader scope. They can not only include strings, but also any other data that Pandas doesn't understand.