Your padding mechanism is not so good, my version is following
import cv2
import numpy as np
ROI_number = 0
factor = 40
decrement = 20
margin = 3
#sorting code source
#https://gist.github.com/divyaprabha123/bfa1e44ebdfc6b578fd9715818f07aec
def sort_contours(cnts, method="left-to-right"):
'''
sort_contours : Function to sort contours
argument:
cnts (array): image contours
method(string) : sorting direction
output:
cnts(list): sorted contours
boundingBoxes(list): bounding boxes
'''
# initialize the reverse flag and sort index
reverse = False
i = 0
# handle if we need to sort in reverse
if method == "right-to-left" or method == "bottom-to-top":
reverse = True
# handle if we are sorting against the y-coordinate rather than
# the x-coordinate of the bounding box
if method == "top-to-bottom" or method == "bottom-to-top":
i = 1
# construct the list of bounding boxes and sort them from top to
# bottom
boundingBoxes = [cv2.boundingRect(c) for c in cnts]
(cnts, boundingBoxes) = zip(*sorted(zip(cnts, boundingBoxes),
key=lambda b:b[1][i], reverse=reverse))
# return the list of sorted contours and bounding boxes
return (cnts, boundingBoxes)
image = cv2.imread("test.png")
#use a black container of same shape to construct new image with gaps
container = np.zeros(image.shape, np.uint8)
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
blur = cv2.GaussianBlur(gray, (9, 9), 0)
thresh = cv2.adaptiveThreshold(blur,255,cv2.ADAPTIVE_THRESH_GAUSSIAN_C, cv2.THRESH_BINARY_INV, 11, 25)
# Dilate to combine adjacent text contours
kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (3,3))
dilate = cv2.dilate(thresh, kernel, iterations=4)
# Find contours, highlight text areas, and extract ROIs
cnts = cv2.findContours(dilate, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
cnts = cnts[0] if len(cnts) == 2 else cnts[1]
#sort so that order remain preserved
cnts = sort_contours(cnts)[0]
for c in cnts:
ROI_number += 1
area = cv2.contourArea(c)
print(area)
x, y, w, h = cv2.boundingRect(c)
x -= margin
y -= margin
w += margin
h += margin
#extract region of interest e.g. the word
roi = image[y : y + h, x : x + w].copy()
factor -= decrement
x = x - factor
#copy the words from the original image to container image with gap factor
container[y : y + h, x : x + w] = roi
cv2.imshow('image', container)
cv2.waitKey()
The output is below, I assume for other images you will have to optimize this code to automatically find optimum threshold values.
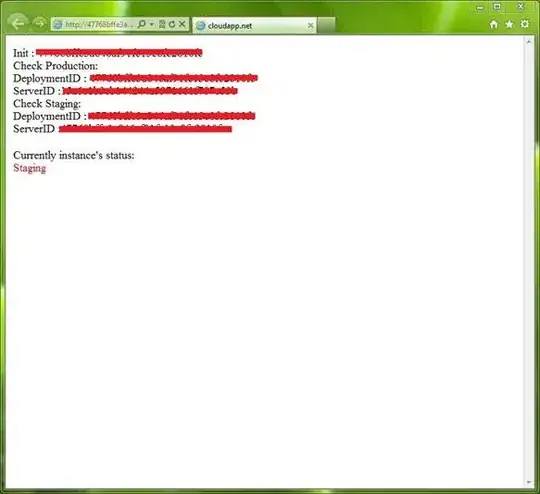
What I did is following
- Extract contours using a threshold value
- Sort contours left to right for correct words order
- Create empty container (new image of same size as original)
- Copy all words from original to new container with padding



