You can achieve this by selecting Allow Upsert in sink settings under the Update method.
Below are my repro details:
- This is the staging table in snowflake which I am loading incremental data to.
- Source file – Incremental data
a) This file contains records that exist in the staging table (StateCode = ‘AK’ & ‘CA’), so these 2 records should be updated in the staging table with new values in Flag.
b) Other 2 records (StateCode = ‘FL’ & ‘AZ’) should be inserted into the staging table.

- Dataflow source settings:

- Adding
DerivedColumn transformation to add a column modified_date which is not in the source file but in the sink table.
- Adding
AlterRow transformation: When you are using the Upsert method, AlterRow transformation is a must to include the upsert condition.
a) In condition, you can mention to upsert the rows only when the unique column (StateCode in my case) is not null.

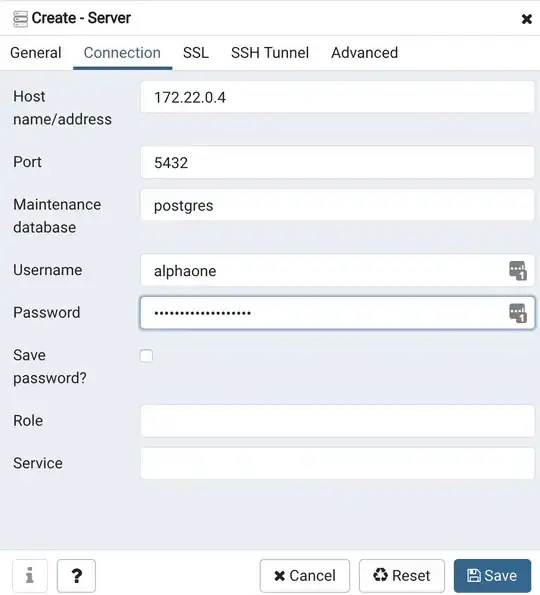
- Adding
sink transformation to AlterRow with Snowflake stage table as sink dataset.

a) In sink settings, select Update method as Allow upsert and provide the Key (unique) column based on which the Upsert should happen in sink table.
- After you run the pipeline, you can see the results in a sink.
a) As StateCode AK & CA already exists in the table, only other column values (flag & modified_date) for those rows are updated.
b) StateCode AZ & FL are not found in the stage (sink) table so, these rows are inserted.














