I am using a remote workstation with nvidia Geforce Gpu , and after compiling and executing when I try to profile this shows up in the screen 
and this is the output when i run nvidia-smi 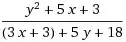
#include <stdio.h>
#include <cuda.h>
#include <math.h>
__global__ void matrixInit(double *matrix, int width, int height, double value){
for(int i = (threadIdx.x + blockIdx.x * blockDim.x); i<width; i+=(blockDim.x * gridDim.x)){
for(int j = (threadIdx.y + blockIdx.y * blockDim.y); j<height; j+=(blockDim.y * gridDim.y)){
matrix[j * width +i] = value;
}
}
}
__global__ void matrixAdd(double *d_A, double *d_B, double *d_C, int width, int height){
int ix = threadIdx.x + blockIdx.x * blockDim.x;
int iy = threadIdx.y + blockIdx.y * blockDim.y;
int stride_x = blockDim.x * gridDim.x;
int stride_y = blockDim.y * gridDim.y;
for(int j=iy; j<height; j+=stride_y){
for(int i=ix; i<width; i+=stride_x){
int index = j * width +i;
d_C[index] = d_A[index-1] + d_B[index];
}
}
}
int main(){
int Nx = 1<<12;
int Ny = 1<<15;
size_t size = Nx*Ny*sizeof(double);
// host memory pointers
double *A, *B, *C;
// device memory pointers
double *d_A, *d_B, *d_C;
// allocate host memory
A = (double*)malloc(size);
B = (double*)malloc(size);
C = (double*)malloc(size);
// kernel call
int thread = 32;
int block_x = ceil(Nx + thread -1)/thread;
int block_y = ceil(Ny + thread -1)/thread;
dim3 THREADS(thread,thread);
dim3 BLOCKS(block_y,block_x);
// initialize variables
matrixInit<<<BLOCKS,THREADS>>>(A, Nx, Ny, 1.0);
matrixInit<<<BLOCKS,THREADS>>>(B, Nx, Ny, 2.0);
matrixInit<<<BLOCKS,THREADS>>>(C, Nx, Ny, 0.0);
//allocated device memory
cudaMalloc(&d_A, size);
cudaMalloc(&d_B, size);
cudaMalloc(&d_C, size);
//copy to device
cudaMemcpy(d_A, A, size, cudaMemcpyHostToDevice);
cudaMemcpy(d_B, B, size, cudaMemcpyHostToDevice);
// Add matrix at GPU
matrixAdd<<<BLOCKS,THREADS>>>(A, B, C, Nx, Ny);
//copy back to host
cudaMemcpy(C, d_C, size, cudaMemcpyDeviceToHost);
cudaFree(A);
cudaFree(B);
cudaFree(C);
return 0;
}
This is my code. in summary, the result shows these 2 warning messages:
==525867== Warning: 4 records have invalid timestamps due to insufficient device buffer space. You can configure the buffer space using the option --device-buffer-size.
==525867== Warning: 1 records have invalid timestamps due to insufficient semaphore pool size. You can configure the pool size using the option --profiling-semaphore-pool-size.
==525867== Profiling result: No kernels were profiled.