I'm currently working on a Chess AI. The idea behind this project is to create a neural network that learns how to evaluate a board state and then traverse the next moves using Monte Carlo tree search to find the "best" move to play (evaluated by the NN).
TL;DR
The NN gets stuck predicting the average evaluation of the dataset and is thereby not learning to predict the evaluation of the board state.
Implementation
Dataset
The dataset is a collection of chess games. The games are fetched from the official lichess database. Only games which have a evaluation score (which the NN is supposed to learn) are included. This reduces the size of the dataset to about 11% of the original.
Data representation
Each move is a datapoint to train the network on.
The input for the NN are 12 arrays of size 8x8 (so called Bitboards), one for each of the 6x2 different pieces and colors.
The move evaluation is normalized to the range [-1, 1] using a scaled tanh function.
Since many evaluations are very close to 0 and -1/1, a percentage of these are dropped aswell, to reduce the variation in the dataset.
Without dropping some of the moves with evaluation close to 0 or -1/1 the dataset would look like this:
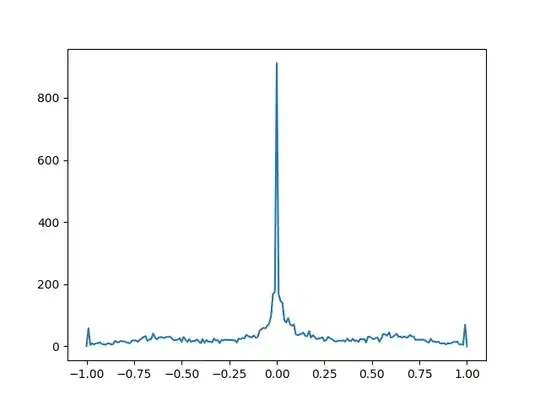
With dropping some, the dataset looks like this and is a lot less focused at one point:
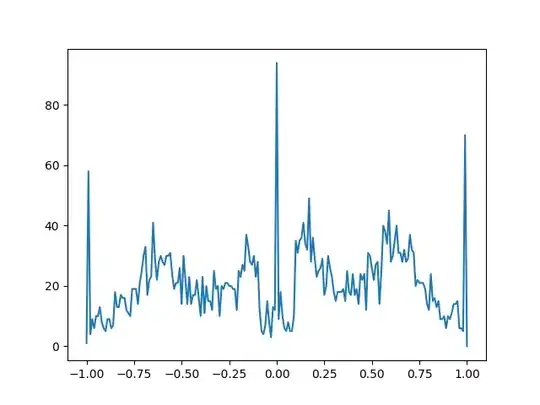
The output of the NN is a single scalar value between -1 and 1, representing the evaluation of the board state. -1 meaning the board is heavily favored for the black player, 1 meaning the board is heavily favored for the white player.
def create_training_data(dataset: DataFrame) -> Tuple[np.ndarray, np.ndarray]:
def drop(indices, fract):
drop_index = np.random.choice(
indices,
size=int(len(indices) * fract),
replace=False)
dataset.drop(drop_index, inplace=True)
drop(dataset[abs(dataset[12] / 10.) > 30].index, fract=0.80)
drop(dataset[abs(dataset[12] / 10.) < 0.1].index, fract=0.90)
drop(dataset[abs(dataset[12] / 10.) < 0.15].index, fract=0.10)
# the first 12 entries are the bitboards for the pieces
y = dataset[12].values
X = dataset.drop(12, axis=1)
# move into range of -1 to 1
y = y.astype(np.float32)
y = np.tanh(y / 10.)
return X, y
The neural network
The neural network is implemented using Keras.
The CNN is used to extract features from the board, then passed to a dense network to reduce to an evaluation. This is based on the NN AlphaGo Zero has used in its implementation.
The CNN is implemented as follows:
model = Sequential()
model.add(Conv2D(256, (3, 3), activation='relu', padding='same', input_shape=(12, 8, 8, 1)))
for _ in range(10):
model.add(Conv2D(256, (3, 3), activation='relu', padding='same'))
model.add(BatchNormalization())
model.add(Conv2D(128, (3, 3), activation='relu'))
model.add(BatchNormalization())
model.add(Conv2D(128, (3, 3), activation='relu'))
model.add(BatchNormalization())
model.add(Flatten())
model.add(Dense(units=64, activation='relu'))
# model.add(Rescaling(scale=1 / 10., offset=0)) required? Data gets scaled in create_training_data, does the Network learn that/does doing that explicitly help?
model.add(Dense(units=1, activation='tanh'))
model.compile(
loss='mean_squared_error',
optimizer=Adam(learning_rate=0.01),
# metrics=['accuracy', 'mse'] # do these influence training at all?
)
Training
The training is done using Keras. Multiple sets of 50k-500k moves are used to train the network. The network is trained for 20 epochs on each move set with a batchsize of 64 and 10% of moves are used for validation.
Afterwards the learning rate is adjusted by 0.001 / (index + 1).
for i, chunk in enumerate(pd.read_csv("../dataset/nm_games.csv", header=None, chunksize=100000)):
X, y = create_training_data(chunk)
model.fit(
X,
y,
epochs=20,
batch_size=64,
validation_split=0.1
)
model.optimizer.learning_rate = 0.001 / (i + 1)
Issues
The NN currently does not learn anything. It converges within a few epochs to a average evaluation of the dataset and does not predict anything depending on the board state.
Example after 20 epochs:
| Dataset Evaluation | NN Evaluation | Difference |
|---|---|---|
| -0.10164772719144821 | 0.03077016 | 0.13241789 |
| 0.6967725157737732 | 0.03180310 | 0.66496944 |
| -0.3644430935382843 | 0.03119821 | 0.39564130 |
| 0.5291759967803955 | 0.03258476 | 0.49659124 |
| -0.25989893078804016 | 0.03316733 | 0.29306626 |
The NN Evaluation is stuck at 0.03, which is the approximate average evaluation of the dataset. It is also stuck there, not continuing to improve.

What I tried
- Increased and decreased NN size
- Added up to 20 extra Conv2D layers since google did that in their implementation aswell
- Removed all 10 extra Conv2D layers since I read that many NN are too complex for the dataset
- Trained for days at a time
- Since the NN is stuck at 0.03, and also doesn't move from there, that was wasted.
- Dense NN instead of CNN
- Did not eliminate the point where the NN gets stuck, but trains faster (aka. gets stuck faster :) )
model = Sequential() model.add(Dense(2048, input_shape=(12 * 8 * 8,), activation='relu')) model.add(Dense(2048, activation='relu')) model.add(Dense(2048, activation='relu')) model.add(Dense(1, activation='tanh')) model.compile( loss='mean_squared_error', optimizer=Adam(learning_rate=0.001), # metrics=['accuracy', 'mse'] ) - Sigmoid activation instead of tanh Moves evaluation from a range of -1 to 1 to a range of 0 to 1 but otherwise did not change anything about getting stuck.
- Epochs, batchsize and chunksize increased and decreased All of these changes did not significantly change the NN evaluation.
- Learning Rate addaption
- Larger learning rates (0.1) made the NN unstable, each time training, converging to either -1, 1 or 0.
- Smaller learning rates (0.0001) made the NN converge slower, but still stuck at 0.03.
Question
What to do? Is there something I'm missing or is there an error?