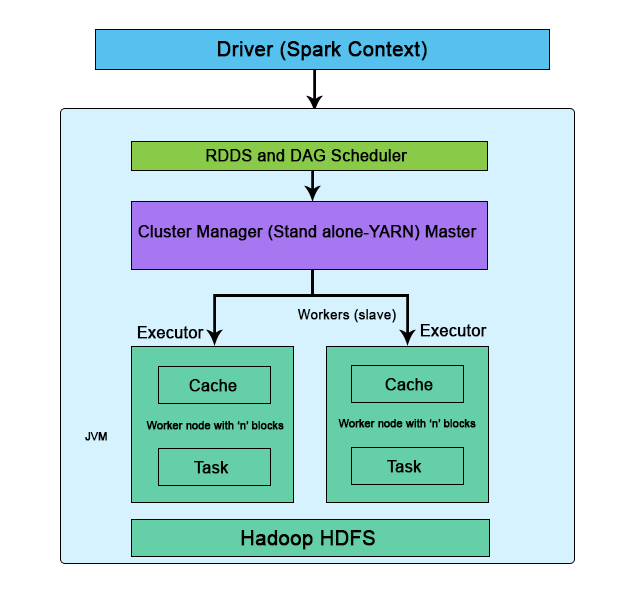
Apache Spark on workloads on 250-500 GB data. B/M was done with 100% and 10% data sets. Jobs run between 250-3000s depending on the type and size. I can force number of executors to be 1 with 1 executor core, but that would be wrong as theoretically only optimum serial job should be written.
– Quiescent 24 mins ago
( URL added )
Thanks for this note. The problem gets ground to answer it :
Q :... "Is such a parameter used in CS ?"
The answer to the questions about the observations on the above depicted problem has nothing to do with DATA-size per-se, the DATA-sizing is important, yet the core understanding is related to the internal functioning of the distributed-computing where overheads matter :
SMALL RDD-DATA
+-------------------E-2-E ( RDD/DAG Spark-wide distribution
|s+------+o | & recollection
|e| | v s| Turn-Around-Time )
|t| DATA | e d |
|u|1x | r a |
|p+------+ h e |
+-------------------+
| |
| |
|123456789.123456789|
Whereas :
LARGER RDD-DATA
+--------:------:------:------:-------------------E-2-E ( RDD/DAG Spark-wide TAT )
|s+------:------:------:------:------+o + |
|e| : : : : | v s v|
|t| DATA : DATA : DATA : DATA : DATA | e d a|
|u|1x :2x :3x :4x :5x | r a r|
|p+------:------:------:------:------+ h e .|
+--------:------:------:------:-------------------+
| |
| | |
|123456789.123456789| |
| |
|123456789.123456789.123456789.123456789.123456789|
( not a multiple of 5x the originally observed E-2-E for "small" DATA ( Spark-wide TAT )
yet a ( Setup & Termination overheads stay about same ~ const. )
a ( a DATA-size variable part need-not yet may grow )
now
show an E-2-E of about ~ 50 TimeUNITs for 5-times more DATA,
that is
for obvious
reasons not 5-times ~ 20 TimeUNITs
as was seen
during the E-2-E TAT from processing in "small"-DATA use-case
as not
all system-wide overheads accumulation
scale with DATA size
For further reading on Amdahl's argument & Gustafson/Barsis promoted scaling, feel free to continue here.

{kind=link}