Hi I have the following data
data = {
"a": 1,
"b": 2,
"c": 3,
"d": 4,
"efgh": [
{
"e": 5,
"f": 6,
"g": 7,
"h": 8
}
]
}
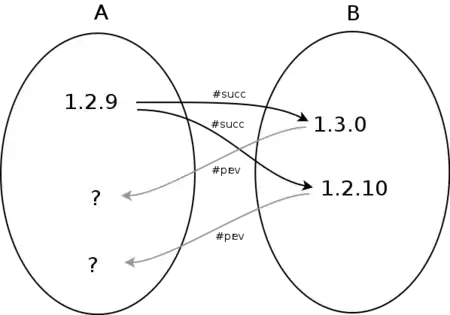
I would like to convert it to pandas data frame with the following format
I have tried with following method
df = pd.DataFrame(data)
df