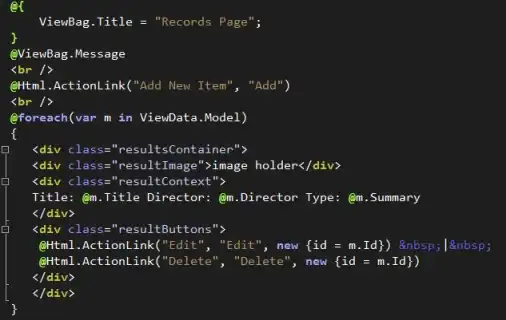
This would give you the main
driver.find_element(By.XPATH, "//*[@role='main']")
DOM Snapshot
If you are looking for the job opening cards, this may help:
driver.find_elements(By.XPATH, "//*[@role='main']//a")
OR
driver.find_elements(By.XPATH, "//*[@role='main']//li[@data-ui = 'job-opening']")
UPDATE TO SHOW THE COMPLETE CODE:
To get only the main element:
driver.get("https://apply.workable.com/caxton")
main_ele = WebDriverWait(driver, 30).until(EC.visibility_of_element_located((By.XPATH, "//*[@role='main']")))
print(main_ele)
Output:
<selenium.webdriver.remote.webelement.WebElement (session="34757b3f076c7ad292e832b683654e29", element="73ee8fcc-807d-4066-a884-46f172d859bb")>
Process finished with exit code 0
Note that main does not contain any text to render and hence webelement is seen in output.
To get the job cards:
driver.get("https://apply.workable.com/caxton")
job_cards = WebDriverWait(driver, 30).until(EC.visibility_of_all_elements_located((By.XPATH, "//*[@role='main']//li[@data-ui = 'job-opening']")))
jobs = [job.text for job in job_cards]
print(jobs)
Output:
['Posted 4 days ago\nEmerging Markets Macro Portfolio Manager\nNew York, New York, United States', 'Posted 4 days ago\nEquity L/S Portfolio Manager\nNew York, New York, United States', 'Posted 4 days ago\nGlobal Macro Portfolio Manager\nNew York, New York, United States', 'Posted 4 days ago\nFixed Income RV Portfolio Manager\nNew York, New York, United States', 'Posted 4 days ago\nFixed Income RV Portfolio Manager\nLondon, England, United Kingdom', 'Posted 13 days ago\nESG Internship\nLondon, England, United Kingdom', 'Posted 26 days ago\nTreasury Operations Supervisor\nLondon, England, United Kingdom', 'Posted about 1 month ago\nCorporate Receptionist & Office Management Assistant\nLondon, England, United KingdomFull time', 'Posted about 2 months ago\nFund Accounting, Vice President\nLondon, England, United KingdomFull time', 'Posted 3 months ago\nFund Accounting, Associate\nNew York, New York, United StatesFull time']
Process finished with exit code 0
Here, there are about 10 job-cards in the page, and first, all the elements are located using visibilit_of_all_elements_located and then looped through each of them to extract the text and appended into a list, which is output finally.


{kind=link}