General thoughts:
RSelenium isn't strictly needed, and you can avoid the overhead of launching a browser. There is an API call, you can see in the browser network tab, which supplies the content of interest, and this can be called with no requirement for additional configuration of the request e.g. headers.
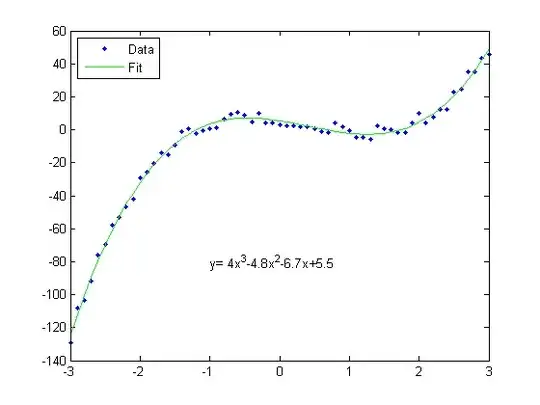
The question of how to extract the items you want from the API response, in the format you want, then becomes a fun challenge (at least to me) as we do not know 1) how many levels of nesting there may be in this response (and possible future ones) 2) whether the level of nesting can vary across listings within a given response for the items of interest 3) whether there will be a commodityCode at a given level (though the pattern appears to be that there is one at the deepest level for a given listing); and we need to consider how we generate columns/lists of equal length for output. These are just some starting considerations that I go on to discuss how I handled below.
The API call:
* You can click on many of the smaller images below to enlarge

The API response:
This request returns nested JSON:
The content of interest is a list of named lists, within the response, accessible via the parent "key" $headingItems:
Each of these named lists is nested as per the levels on the webpage:
You can see the repeated accessor key of headingItems (red boxed), with the first shown above as the parent list stored in data in code to follow.
Below that, indicated by level (orange boxed), are the expanded entries you are after; nested within the response JSON.
Finally, we have the descriptions (green boxed) which contains html for the descriptive text you are after, with English and Norwegian versions of the text:

In addition to this, there is, where present, a commodityCode key within the nested headingItems:
Approach and challenges:
Given that the commodityCode can be at different levels and may not be present (unless assumed to always be present at greatest depth of a given listing), and that it is unknown how many levels of headingItem there can be, the approach I chose was to use regex to identify the relevant child named list's names in a boolean mask (though for purposes here we could just say logical vector); one mask for English headers and one for the commodity codes. I processed each child list separately, using purrr::map and applying a custom function to extract data as a data.table/data.frame.
Example mask (descriptions|text):

The TRUE values are for the following chained accessors (chaining dependent on depth):
Notice how some accessor paths are repeated. This means therefore, that I do not use the mask to retrieve the names and extract the associated values. Instead, I keep the TRUE and FALSE values and thereby have equal lengths for both vectors. I combine the two logical vectors as columns within a data.table; along with the entire set of values within the child list:
This work is done within the custom function get_data, where I also then do the following steps:
- I filter for only rows where there is a TRUE value i.e. a value I wish to retrieve
- Apply a function utilizing gsub(), to remove non-breaking whitespace, and read_html() to convert those descriptions which are actual html to text. N.B. Some entries are not actually html and are handled by the
if statement. In those cases, the input value is returned:
- At this point the codes and descriptions/text are in a single column:

I use the booleans in commodity_code to update that columns value where TRUE to match the text column, and wrap in if to replace FALSE with NA.

- Knowing that there is actually a 1 row offset between description and associated code, where applicable, I then shift the commodity column values down one row to correctly align with descriptions:
- I then keep only the rows where description_header_flag is TRUE:
- Finally, I remove the now not needed flag column:
This leaves me with a clean data.table to return from the function.
Generating the final output:
As map() applying the custom function above to a list returns a list of data.tables, I then simply call rbindlist() to combine these into a single data.table:
df <- rbindlist(map(data, get_data))
This can then be written to csv for example.
fwrite(df, 'result.csv')
Example rows in df:
N.B. I return a data.table as you showed 2 columns in your desired output.
R:
library(jsonlite)
library(tidyverse)
library(rvest)
library(data.table)
get_data <- function(x) {
y <- x %>% unlist(recursive = T)
t <- data.table(text = y, description_header_flag = grepl("(?:headingItems\\.)description\\.en$|^description.en$", names(y)), commodity_code = grepl("*commodityCode$", names(y)))
t <- t[description_header_flag | commodity_code, ]
t$text <- map2(t$text, t$description_header_flag, ~ gsub(intToUtf8(160), " ", if (.y & str_detect(.x, pattern = "<div>|<p>")) {
html_text(read_html(.x))
} else {
.x
}))
t$commodity_code <- map2(t$commodity_code, t$text, ~ if (.x) {
.y
} else {
NA
})
t[, commodity_code := c(NA, commodity_code[.I - 1])]
t <- t[description_header_flag == T, ]
t[, description_header_flag := NULL]
return(t)
}
data <- jsonlite::read_json("https://tolltariffen.toll.no/api/search/headings/03.02") %>% .$headingItems
df <- rbindlist(map(data, get_data))
fwrite(df, "result.csv")
Sample output:
Credits:
gsub solution taken from: @shabbychef here
row shift solution adapted from: @Gary Weissman here
















