I want to binarize an image for OCR. I have attached the code which take image data as input and return binary image and this method works for most of the image.
For e.g,
- Original:
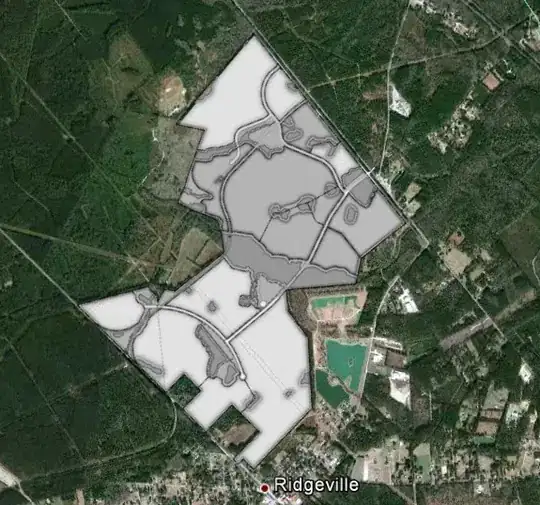
- Result:
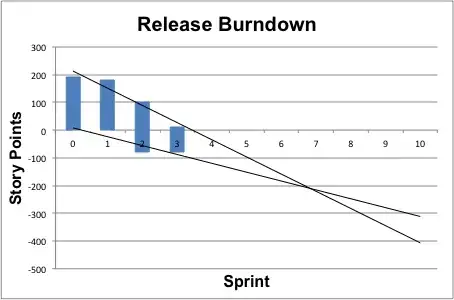
def preprocessing(image):
image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
blured1 = cv2.medianBlur(image, 3)
blured2 = cv2.medianBlur(image, 51)
divided = np.ma.divide(blured1, blured2).data
normed = np.uint8(255 * divided / divided.max())
th, image = cv2.threshold(normed, 100, 255, cv2.THRESH_BINARY | cv2.THRESH_OTSU)
image = cv2.erode(image, np.ones((3, 3), np.uint8))
image = cv2.dilate(image, np.ones((3, 3), np.uint8))
return image
But when I applied the same method on below attached images it won't work as per the expectation. It should give image which has readable text for tesseract input.
- Original Image 1:
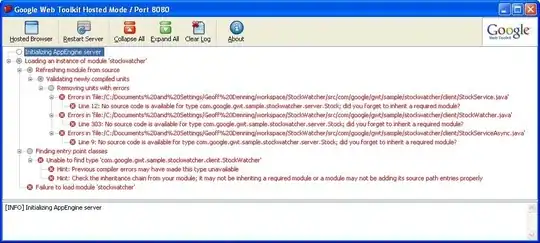
- Pre processed image:

- Original Image 2:
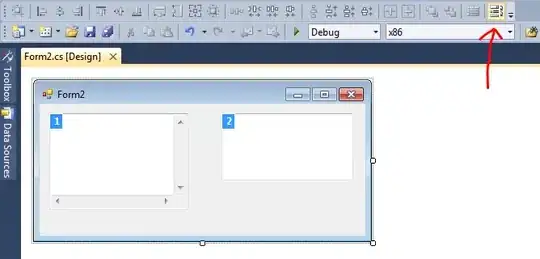
- Pre processed image:
