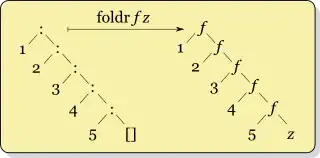
Both expressions return the in order concatenation of all sublists in the rightmost argument, so they are functionally identical, at least for finite sublists.
Let's check using the Haskell ghci interpreter:
$ ghci
GHCi, version 8.10.5: https://www.haskell.org/ghc/ :? for help
...
λ>
λ> xss = [[1,2], [3,4,5], [6,7,8,9]]
λ>
λ> foldr (++) [] xss == foldl (++) [] xss
True
λ>
λ> foldr (++) [] [[1,2], [3,4,5], [6,7,8,9]]
[1,2,3,4,5,6,7,8,9]
λ>
λ> foldl (++) [] [[1,2], [3,4,5], [6,7,8,9]]
[1,2,3,4,5,6,7,8,9]
λ>
But that's not the whole story. For example, any programmer who has been thru the usual lectures about sorting algorithms knows that bubble sort and QuickSort are functionally equivalent. Both algorithms return the ordered version of the input array.
But QuickSort is practical, and bubble sort is useless except for small input arrays.
It is a bit similar here.
Let's turn statistics on in our ghci interpreter:
λ>
λ> :set +s
λ>
λ> length $ foldl (++) [] (replicate 5000 [1,2,3,4])
20000
(3.31 secs, 4,124,759,752 bytes)
λ>
λ> length $ foldl (++) [] (replicate 10000 [1,2,3,4])
40000
(16.94 secs, 17,172,001,352 bytes)
λ>
So if we double the number of input sublists, the volume of memory allocations is multiplied by 4, not 2. The algorithm is quadratic here, hence horribly slow, like bubble sort.
And no, replacing foldl by its strict sibling foldl' will not help. The root of the problem is that operator (++) has to duplicate its left operand, because it is not feasible in Haskell to just alter its last pointer to next node, like you would do in C/C++. However, operator (++) can just use a simple pointer to its right operand, because the right operand is immutable, as is any Haskell named value.
In summary, for the left operand, immutability works against us. For the right operand, it works for us.
In the case of foldl, the left operand is the accumulator. So we repeatedly have to duplicate our (large and growing) accumulator. This is what breaks the performance symmetry between foldl and foldr.
We can readily check that the performance of foldr is much better:
λ>
λ> length $ foldr (++) [] (replicate 5000 [1,2,3,4])
20000
(0.02 secs, 1,622,304 bytes)
λ>
λ> length $ foldr (++) [] (replicate 10000 [1,2,3,4])
40000
(0.02 secs, 3,182,304 bytes)
λ>
because here dynamic memory allocation is multiplied by 2, not 4.