I have two dataframes:
Ranking
 (picture as example)
(picture as example)
structure(list(`1` = c("GLD", "GLD", "GLD", "GLD", "GLD", "GLD"
), `2` = c("VT", "VT", "VT", "VT", "BIL", "VT"), `3` = c("BIL",
"BIL", "BIL", "BIL", "VT", "BIL"), `4` = c("UUP", "UUP", "UUP",
"UUP", "UUP", "UUP"), `5` = c("RSP", "RSP", "RSP", "RSP", "RSP",
"RSP")), row.names = c("2008-02-01", "2008-03-01", "2008-04-01",
"2008-05-01", "2008-06-01", "2008-07-01"), class = "data.frame")
Returns
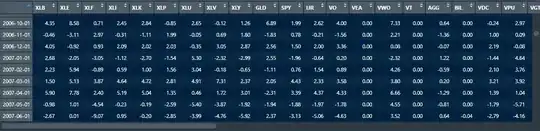 (picture as example)
(picture as example)
structure(list(BIL = c(0.04, -0.22, -0.02, 0.13, 0.07, -0.07),
GLD = c(-6, -4.16, 0.92, 4.52, -1.44, -9.29), RSP = c(-2.24,
5.72, 2.65, -10.16, -0.5, 2.96), UUP = c(-2.4, 0.94, 0.44,
-0.97, 1.02, 5.37), VT = c(0, 0, 0, 0, 0, -1.85)), row.names = c("2008-02-01",
"2008-03-01", "2008-04-01", "2008-05-01", "2008-06-01", "2008-07-01"
), class = "data.frame")
What I want is create a new dataframe with the same structure than Ranking but with the value of Returns.
Something like this
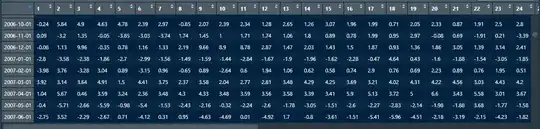
Right now I´m using two For Loop:
for (i in rownames(Ranking)){
for (x in colnames(Ranking)){
stock = as.character(Ranking[i,x])
Solution[i,x] = Returns[i,stock]
}
}
But I would like to use something more efficient. Any idea?