First, I do not think that your algorithm is O(N) at all. An O(N) algorithm would typically loop through every element in the vector. In your case you have two nested loops and the inside loop does not seem to be constant time.
But regardless I did two versions, one for sorted and another for unsorted series (hash maps).
template< typename T >
int findLongestSorted( T& sorted ) {
int counter = 1;
int maxcount = 1;
int last = sorted[0];
for ( int j=1; j<sorted.size(); ++j ) {
int num = sorted[j];
if ( num == last ) continue;
if ( num == last+1 ) {
counter++;
} else {
if ( counter > maxcount ) maxcount = counter;
counter = 1;
}
last = num;
}
if ( counter > maxcount ) maxcount = counter;
return maxcount;
}
template< typename T >
int findLongestUnsorted( T& set ) {
int maxcount = 1;
for( int num : set ){
int counter = 1;
while ( set.find(num+counter) != set.end() ) counter++;
if ( counter > maxcount ) maxcount = counter;
}
return maxcount;
}
Second, I do not trust LeetCode for benchmarking. I believe it counts compile time as well as process startup as well, which can be dominant and ruin your benchmarks.
I would use Google Benchmarks for this, it is true and tested. To define a benchmark, you need to create two test cases which I do templated such that I can be sure I am comparing apples to apples.
template< typename T >
int test( const std::vector<int>& );
template<>
int test<std::vector<int>>(const std::vector<int>& nums) {
if ( nums.empty() ) return 0;
std::vector<int> sorted(nums);
std::sort(sorted.begin(),sorted.end());
return findLongestSorted( sorted );
}
template<>
int test<std::set<int>>(const std::vector<int>& nums ) {
if ( nums.empty() ) return 0;
std::set<int> sorted( nums.begin(), nums.end() );
return findLongestSorted( sorted );
}
template<>
int test<std::multiset<int>>(const std::vector<int>& nums ) {
if ( nums.empty() ) return 0;
std::multiset<int> sorted( nums.begin(), nums.end() );
return findLongestSorted( sorted );
}
template<>
int test<std::unordered_set<int>>(const std::vector<int>& nums ) {
if ( nums.empty() ) return 0;
std::unordered_set<int> set( nums.begin(), nums.end() );
return findLongestUnsorted( set );
}
template<>
int test<std::unordered_multiset<int>>(const std::vector<int>& nums ) {
if ( nums.empty() ) return 0;
std::unordered_multiset<int> set( nums.begin(), nums.end() );
return findLongestUnsorted( set );
}
Then it is just a matter of creating a vector of random numbers and hooking up with the test harness
template< typename T, size_t numel >
static void Benchmark(benchmark::State& state) {
std::random_device rd;
std::mt19937 gen(rd());
std::uniform_int_distribution<int> dist(0,4*numel);
std::vector< int > golden( numel );
for ( int& value : golden ) value = dist(gen);
for (auto _ : state) {
int result = test<T>( golden );
benchmark::DoNotOptimize(result);
}
}
constexpr size_t NLOOPS = 100000;
BENCHMARK(Benchmark<std::vector<int>,NLOOPS>);
BENCHMARK(Benchmark<std::set<int>,NLOOPS>);
BENCHMARK(Benchmark<std::unordered_set<int>,NLOOPS>);
BENCHMARK(Benchmark<std::unordered_set<int>,NLOOPS>);
BENCHMARK(Benchmark<std::unordered_multiset<int>,NLOOPS>);
Link to Quick Benchmark Cpp
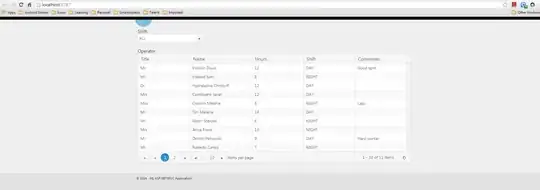
Update: the algorithm above PASSES leetcode with a score of 80% above all other C++ submissions.


{kind=link}