I am trying to extract timings from this page. I would like these timings in text form to do more processing.
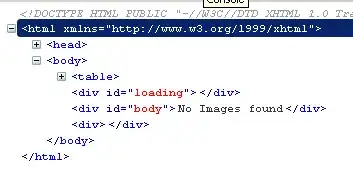
I have tried this code:
elements = driver.find_elements(by=By.CLASS_NAME, value="lyr_timeCount")
for elem in elements:
times.append(elem.text)
using the selenium driver. However, elements is an empty list. I have also tried using the xPath with the same result. I have also tried this using beautiful soup with the same result.
page = requests.get(url)
soup = BeautifulSoup(page.content, 'html.parser')
times = soup.find_all('time', {'class': 'lyr_sqResTime'})
Both have resulted in empty lists. How can I extract the timing data from this webpage using either method?