Your lexer tokenizes independently from your parser. If your parser tries to match a BUFFER token, the lexer does not take this info into account. In your case with input like: "blah blah blah", the lexer creates 3 IDENT tokens, not a single BUFFER token.
What you need to "tell" your lexer is that when you're inside a tag (i.e. you encountered a LD tag), a IDENT token should be created, and when you're outside a tag (i.e. you encountered a RD tag), a BUFFER token should be created instead of an IDENT token.
In order to implement this, you need to:
- create a
boolean flag inside the lexer that keeps track of the fact that you're in- or outside a tag. This can be done inside the @lexer::members { ... } section of your grammar;
- after the lexer either creates a
LD- or RD-token, flip the boolean flag from (1). This can be done in the @after{ ... } section of the lexer rules;
- before creating a
BUFFER token inside the lexer, check if you're outside a tag at the moment. This can be done by using a semantic predicate at the start of your lexer rule.
A short demo:
grammar g;
options {
output=AST;
ASTLabelType=CommonTree;
}
@lexer::members {
private boolean insideTag = false;
}
start
: body EOF -> body
;
body
: (tag | loop | partial | BUFFER)*
;
tag
: LD IDENT RD -> IDENT
;
loop
: LD LOOP IDENT RD body LD END_LOOP IDENT RD -> ^(LOOP body IDENT IDENT)
;
partial
: LD PARTIAL IDENT RD -> ^(PARTIAL IDENT)
;
LD @after{insideTag=true;} : '{';
RD @after{insideTag=false;} : '}';
LOOP : '#';
END_LOOP : '/';
PARTIAL : '>';
SPACE : (' ' | '\t' | '\r' | '\n') {$channel=HIDDEN;};
IDENT : (LETTER | '_') (LETTER | '_' | DIGIT)*;
BUFFER : {!insideTag}?=> ~(LD | RD)+;
fragment DIGIT : '0'..'9';
fragment LETTER : ('a'..'z' | 'A'..'Z');
(note that you probably want to discard spaces between tag, so I added a SPACE rule and discarded these spaces)
Test it with the following class:
import org.antlr.runtime.*;
import org.antlr.runtime.tree.*;
import org.antlr.stringtemplate.*;
public class Main {
public static void main(String[] args) throws Exception {
String src = "{foo}{#bar}blah blah blah{zed}{/bar}{>foo2}{#bar2}" +
"This Should Be Parsed as a Buffer.{/bar2}";
gLexer lexer = new gLexer(new ANTLRStringStream(src));
gParser parser = new gParser(new CommonTokenStream(lexer));
CommonTree tree = (CommonTree)parser.start().getTree();
DOTTreeGenerator gen = new DOTTreeGenerator();
StringTemplate st = gen.toDOT(tree);
System.out.println(st);
}
}
and after running the main class:
*nix/MacOS
java -cp antlr-3.3.jar org.antlr.Tool g.g
javac -cp antlr-3.3.jar *.java
java -cp .:antlr-3.3.jar Main
Windows
java -cp antlr-3.3.jar org.antlr.Tool g.g
javac -cp antlr-3.3.jar *.java
java -cp .;antlr-3.3.jar Main
You'll see some DOT-source being printed to the console, which corresponds to the following AST:
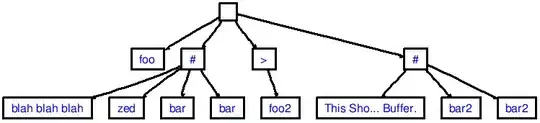
(image created using graphviz-dev.appspot.com)