Sidenote: I don't think the size calculation expression is safe for the reason you seem to think (ul): https://cppinsights.io/s/c34003a4
The code as given should always fail with bad_alloc because you didn't account for the segment manager overhead:
Fixing it e.g. like this runs in 5s for me:
#include <boost/interprocess/managed_shared_memory.hpp>
namespace bip = boost::interprocess;
int main() {
auto id_ = "shmTest";
size_t size_ = 2ul << 30;
bip::shared_memory_object::remove(id_);
bip::managed_shared_memory sm(bip::create_only, id_, size_ + 1024);
auto data_ = sm.construct<char>("Data")[size_]('\0');
}

Changing to
auto data_ = sm.construct<char>("Data")[size_]();
makes no significant difference:
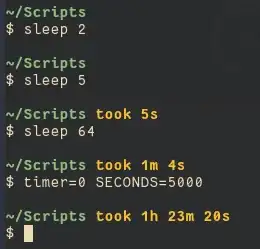
If you want opaque char arrays, just could just use a mapped region directly:
#include <boost/interprocess/shared_memory_object.hpp>
#include <boost/interprocess/mapped_region.hpp>
namespace bip = boost::interprocess;
int main() {
auto id_ = "shmTest";
size_t size_ = 2ul << 30;
bip::shared_memory_object::remove(id_);
bip::shared_memory_object sm(bip::create_only, id_, bip::mode_t::read_write);
sm.truncate(size_);
bip::mapped_region mr(sm, bip::mode_t::read_write);
auto data_ = static_cast<char*>(mr.get_address());
}
Now it's significantly faster:
BONUS
If you insist you can do raw allocation from the segment:
auto data_ = sm.allocate_aligned(size_, 32);
Or, you can just use the segment as it intended, and let is manage your allocations:
#include <boost/interprocess/managed_shared_memory.hpp>
#include <boost/interprocess/containers/vector.hpp>
#include <boost/interprocess/allocators/allocator.hpp>
namespace bip = boost::interprocess;
using Seg = bip::managed_shared_memory;
template <typename T> using Alloc = bip::allocator<T, Seg::segment_manager>;
template <typename T> using Vec = bip::vector<T, Alloc<T>>;
int main() {
auto id_ = "shmTest";
size_t size_ = 2ul << 30;
bip::shared_memory_object::remove(id_);
bip::managed_shared_memory sm(bip::create_only, id_, size_ + 1024);
Vec<char>& vec_ = *sm.find_or_construct<Vec<char>>("Data")(size_, sm.get_segment_manager());
auto data_ = vec_.data();
}
This takes a little more time:
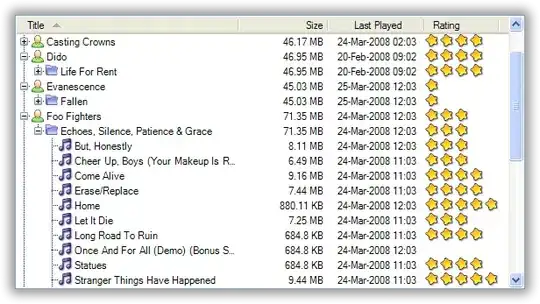
But for that you get enormous flexibility. Just search some of my existing posts for examples using complicated data structures in managed shared memory: https://stackoverflow.com/search?tab=newest&q=user%3a85371%20scoped_allocator_adaptor



