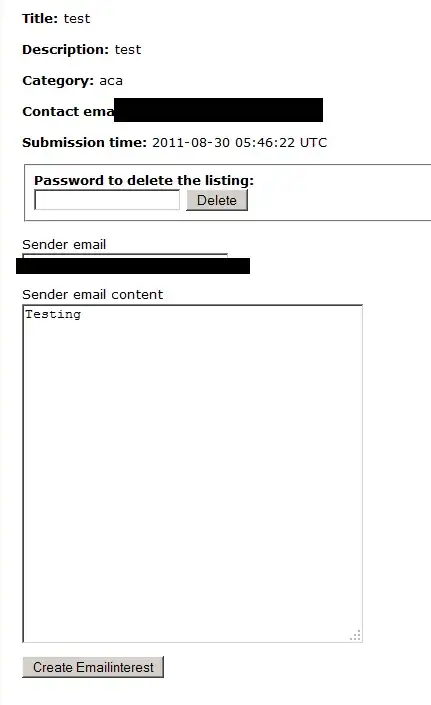
Based on the data and code below, how can I sort the bars in descending order for each group?
Purpose: To show count of each FF in descending order for each city by district. This will then show me which city in which district has the highest count of a particular FF. Where FF = Flood factor (risk of flooding) ranging from 1 to 10 so, the plot will show the dominant FF in each city in a district.
Code + data:
df_sample = structure(list(City = c("A", "A", "A", "A", "A", "A", "A", "A",
"A", "A", "A", "A", "A", "A", "A", "A", "A", "A", "A", "A", "A",
"A", "A", "A", "A", "A", "A", "A", "A", "B", "B", "B", "B", "B",
"B", "B", "B", "B", "B", "B", "B", "B", "B", "B", "B", "B", "B",
"B", "B", "C", "C", "C", "C", "C", "D", "D", "D", "D", "D", "D",
"D", "D", "D", "D", "D", "D", "D", "D", "D", "E", "E", "E", "E",
"E", "E", "E", "E", "E", "F", "F", "F", "F", "F", "F", "F", "F",
"F", "F", "F", "F", "F", "F", "F", "F", "F", "F", "F", "F", "F"
), District = c("D1", "D1", "D1", "D1", "D1", "D1", "D1", "D1",
"D1", "D1", "D1", "D1", "D1", "D1", "D1", "D1", "D1", "D1", "D1",
"D1", "D1", "D1", "D1", "D1", "D1", "D1", "D1", "D1", "D1", "D1",
"D1", "D1", "D1", "D1", "D1", "D1", "D1", "D1", "D1", "D1", "D1",
"D1", "D1", "D1", "D1", "D1", "D1", "D1", "D1", "D1", "D1", "D1",
"D1", "D1", "D2", "D2", "D2", "D2", "D2", "D2", "D2", "D2", "D2",
"D2", "D2", "D2", "D2", "D2", "D2", "D2", "D2", "D2", "D2", "D2",
"D2", "D2", "D2", "D2", "D2", "D2", "D2", "D2", "D2", "D2", "D2",
"D2", "D2", "D2", "D2", "D2", "D2", "D2", "D2", "D2", "D2", "D2",
"D2", "D2", "D2"), FF = c(1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L,
1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L,
1L, 1L, 1L, 1L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L,
2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 3L, 3L, 3L, 3L, 3L, 1L, 1L, 1L,
1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 2L, 2L, 2L, 2L,
2L, 2L, 2L, 2L, 2L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L,
3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L)), class = "data.frame", row.names = c(NA,
-99L))
# Plot
df_sample %>%
arrange(desc(FF)) %>%
ggplot(aes(x = City,
y = FF,
fill = District)) +
geom_bar(position = "dodge",
stat = "identity")