When running a job as a pipeline in Gitlab Runner's K8s pod, the job gets completed successfully only when running on a small instance like m5*.large which offers 2 vCPUs and 8GB of RAM. We set a limit for the build, helper, and services containers mentioned below. Still, the job fails with an Out Of Memory (OOM) error, getting the process node killed by cgroup when running on an instance way more powerful like m5d*.2xlarge for example which offers 8 vCPUs and 32GB of RAM.
Note that we tried to dedicate high resources to the containers, especially the build one in which the node process is a child process of this and nothing changed when running on powerful instances; the node process still got killed because of OOM, each time we give it more memory, the node process consumed higher memory and so on.
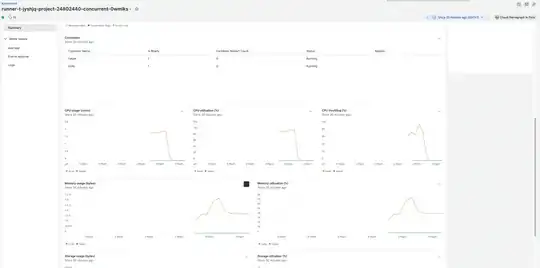
Also, regarding the CPU usage, in powerful instances, the more vCPUs we gave it, the more is consumed and we noticed that it has CPU Throtelling at ~100% almost all the time, however, in the small instances like m5*.large, the CPU throttling didn't pass the 3%.
Note that we specified a maximum of memory that be used by the node process but it looks like it does not take any effect. We tried to set it to 1GB, 1.5GB and 3GB.
NODE_OPTIONS: "--max-old-space-size=1536"
Node Version
v16.19.0
Platform
amzn2.x86_64
Logs of the host where the job runs
"message": "oom-kill:constraint=CONSTRAINT_MEMCG,nodemask=(null),cpuset=....
....
"message": "Memory cgroup out of memory: Killed process 16828 (node) total-vm:1667604kB
resources request/limits configuration
memory_request = "1Gi"
memory_limit = "4Gi"
service_cpu_request = "100m"
service_cpu_limit = "500m"
service_memory_request = "250Mi"
service_memory_limit = "2Gi"
helper_cpu_request = "100m"
helper_cpu_limit = "250m"
helper_memory_request = "250Mi"
helper_memory_limit = "1Gi"
Resource consumption of a successful job running on m5d.large

Resource consumption of a failing job running on m5d.2xlarge