Sorry in advance for I'm an R newbie. So I was working on Divvy Bike Share data (details see here. Here is a subset of my df:
I wanted to visualize the total ridership count (how many times bikes are used) as compressed and shown in a week. I tried two blocks of codes, with the only difference being summarize() - the second one has "month" inside the function. I don't understand what resulted in this difference in y-axis values in the two graphs.
p1 <- df %>%
group_by(member_casual, day_of_week) %>%
summarize(total_rides = n()) %>%
ggplot(aes(x = day_of_week, y = total_rides, fill = member_casual)) +
geom_col(position = "dodge") +
labs(title = "Total Rides by Days in a Week", subtitle = "Casual Customers vs. Members", y = "ride times count (in thousands)") +
theme(axis.title.x = element_blank()) +
scale_fill_discrete(name = "") +
scale_y_continuous(labels = label_number(scale = 1e-3, suffix = "k"))
p1
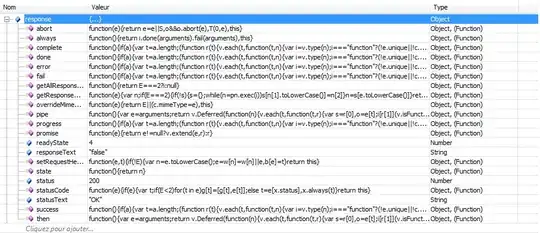
p2 <- df %>%
group_by(member_casual, day_of_week, month) %>%
summarize(total_rides = n()) %>%
ggplot(aes(x = day_of_week, y = total_rides, fill = member_casual)) +
geom_col(position = "dodge") +
labs(title = "Total Rides by Days in a Week", subtitle = "Casual Customers vs. Members", y = "ride times count (in thousands)") +
theme(axis.title.x = element_blank()) +
scale_fill_discrete(name = "") +
scale_y_continuous(labels = label_number(scale = 1e-3, suffix = "k"))
p2
I tested the tables generated before a plot is visualized, so I tried the following blocks:
df %>%
group_by(member_casual, day_of_week) %>%
summarize(total_rides = n())
df %>%
group_by(member_casual, day_of_week, month) %>%
summarize(total_rides = n())
I guess I understand by adding more elements in group_by, the resulting table will become more catagorized or "grouped". However, the total should always be the same, no? For example, if you add up all the casual & Sundays (as separated into 12 months) in tibble 2, you'll get exactly the number in tibble 1 - 392107, the same number as shown in p1, not p2. So this exacerbated my confusion.
So in a word, I have two questions:
- Why the difference in p1 and p2? How could I have avoided such errors in the future?
- Where does the numbers come in p2?
Any advice would be greatly appreciated. Thank you!
