First I will clarify some terms so that we are speaking the same language. You are appear to be using field and record interchangeably.
A FILE (aka TABLE for SQL folk, 'QUOTES' in this case) contains 0 or more RECORDS. Each record is made up of multiple ATTRIBUTES (aka FIELD). You can reference these attributes using dictionary items (which can also create derived fields)
In this case you want to find the longest length of data accessed via the Part_Nbr dictionary, correct?
Assuming this is correct, you can do it as follows
Use a dictionary Item
Step 1: Create a I-type dictionary item (derived field). Let us call it Part_Nbr_Len. You can do this at the command line using UNIENTRY DICT QUOTES Part_Nbr_Len as per the image below.
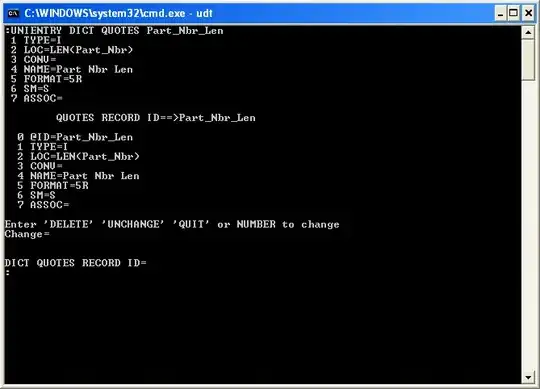
- Type = I (aka Derived Field)
- LOC = LEN(Part_Nbr) (The field is the number of 1 byte characters in the Part_Nbr field)
- FORMAT = 5R (Right-aligned makes it treat this field as a number for sorting purposes)
- SM = S (This field is a single value)
Step 2: List the file in descending order by Part_Nbr_Len and optionally as I have done, also list the actual Part_Nbr field. You do this by the following command.
LIST QUOTES BY.DSND Part_Nbr_Len Part_Nbr_Len Part_Nbr
Temporary command-line hack
Alternatively, if you don't want something permanent, you could do a bit of a hack at the command line:
list QUOTES BY.DSND EVAL "10000+LEN(Part_Nbr)" EVAL "LEN(Part_Nbr)" Part_Nbr
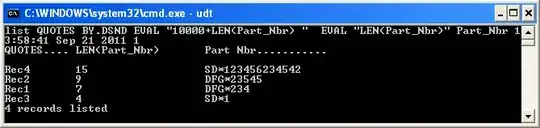
Okay, let's break it down:
list -> May or may not be important that this is lowercase. This enables you to use 'EVAL' regardless of your account flavor.
EVAL -> Make a derived field on the fly
10000+LEN(Part_Nbr) -> Sorting of derived field is done by ASCII order. This means 9 would be listed before 15 when sorting by descending order. The + 10000 is a hack that means ASCII order will be the same as numeric order for numbers between 0 and 9999 which should cover the possible range in your case
EVAL "LEN(Part_Nbr)" -> Display the actual field length for you.
EDIT
Solve via code for MultiValued lists
If you have a MultiValued (and/or Sub-MultiValued) attribute, you will be required to use a subroutine to determine the length of the largest individual item. Fortunately, you can have a I-type dictionary item call a subroutine.
The first step will be to write, compile and catalog a simple UniBASIC subroutine to do the processing for you:
SUBROUTINE SR.MV.MAXLEN(OUT.MAX.LEN, IN.DATA)
* OUT.MAX.LEN : Returns the length of the longest MV/SMV value
* IN.ATTRIBUTE : The multivalued list to process
OUT.MAX.LEN = 0
IN.DATA = IN.DATA<1> ;* Sanity Check. Ensure only one attribute
IF NOT(LEN(IN.DATA)) THEN RETURN ;* No Data to check
LOOP
REMOVE ELEMENT FROM IN.DATA SETTING DELIM
IF LEN(ELEMENT) > OUT.MAX.LEN THEN OUT.MAX.LEN = LEN(ELEMENT)
WHILE DELIM
REPEAT
RETURN
To compile a program it must be in a DIR type file. As an example, if you have the code in the 'BP' file, you can compile it with this command:
BASIC BP SR.MV.MAXLEN
How you catalog it depends upon your needs. Their are 3 methods:
- DIRECT
- LOCAL -> My suggestion if you only want it in the current account
- GLOBAL -> My suggestion if you want it to work across all accounts
If you have the program compiled in the 'BP' file, the catalog commands for the above would be:
CATALOG BP SR.MV.MAXLEN DIRECTCATALOG BP SR.MV.MAXLEN LOCALCATALOG BP SR.MV.MAXLEN
After the subroutine has been cataloged, you will need to have the LOC field (attribute 2) of the dictionary item Part_Nbr_Len (as per first part of this answer) updated to call the subroutine and pass it the field to process:
SUBR("SR.MV.MAXLEN", Part_Nbr)
Which gives you:
