So I'm trying to do a networkanalysis with igraph in R, but I'm a R newbie.
My Excel database looks like this.. just bigger.
test<-separate(ID_test, 'Contacts 1', paste("Contacts", 1:20, sep="_"), sep=",", extra="drop")
m <- as.matrix(test)
el <- cbind(m[, 1], c(m[, -1]))
el2<-na.omit(el)
testel<- graph_from_edgelist(el2, directed=FALSE)
plot(testel)
I sepArated the data from Contacts to multiple columns and transformed the data to a matrix so I can create an edgelist with cbind.
After that I deleted every row where an NA is present.
With igraph I could then plot my undirected network.
The Problem is that I have duplicate rows where the IDs are just switched between V1 and V2.
Therefore I have f.e. ID_009 and ID003 twice in my network cause the edgelist looks like this..
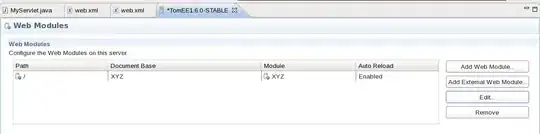
As you can see the first and the last row are basically the same just with switched values between V1 and V2.
I already tried multiple solutions but none seems to work for me.
el4<-el3[!duplicated(el[c("V1", "V2")]),] #doesnt recognize the right duplicates as in the example above
el4<-el3[!duplicated(paste(pmin(V1, V2), pmax(V1, V2)))] #Error in pmin(V1, V2) : object 'V1' not found
el4<-el3[!duplicated(paste(pmin("V1", "V2")), pmax("V1", "V2"))] # creates values with which i cant create an network
g <- graph_from_edgelist(unique(rbind(el2[, 1:2])), directed = FALSE) #doesnt change anything
plot(g)