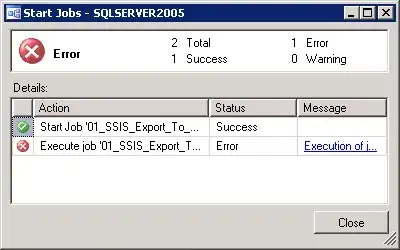
I feel like I should know this and like I have a knot in my brain. I have data that looks like this:
there a scale going 1, 1.25, 1.5, 1.75, 2, 2.25, 2.5, 2.75, 3 etc and for each scale point there's a certain number of people who selected it - none of the data points is 0.
Yet, the histogram looks like this with the weird spaces in between. Why?
Thank you!