I have a scatterplot, just like the one below:
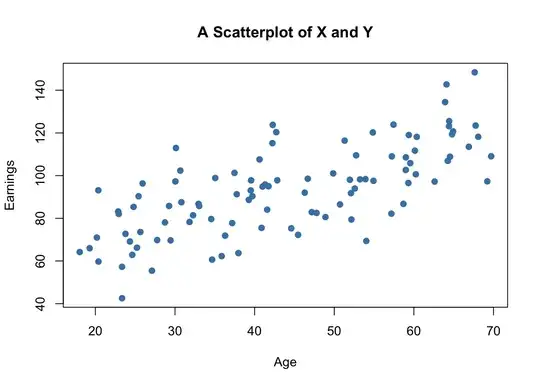
Let's say I want to create a new column, named QUADRANT, which contains the number that represents a quadrant. For instance, if the point has the y axis between 150 and 120, and the x axis between 0 and 20, it will receive 1. If the y is between 150 and 120, and the x axis between 20 and 40, it will receive 2. And I would do that until the whole quadrant is fullfilled, or at least with y going from 0 to 150, and x going from 0 to 80 and I'm manually defining those limits.
The only thing I could think of was using np.where(), however, I would have to write dozens of lines of code. I was hoping there was a smart way of doing this.