Bootstrap sampling in Pandas with weighting on multiple levels
Given a table as the one in the example below (with possible additional columns), I want to bootstrap samples where countries and fruits are sampled independently uniformly at random.
For each country, there is a number of fruits, a number that varies between countries.
To make it clear what I am looking for, I have created a series (1-4) of sampling strategies, starting simple and getting more and more towards what I want:
Sample M fruits per country ...
- ... uniformly.
- ... inversely proportional to the number of occurrences of the fruit.
- ... (on average) uniformly, but bootstrap the countries.
- ... (on average) inversely proportional to the number of occurrences of the fruit, but bootstrap the countries.
As a minimal example for my question, I have chosen countries and fruits.
| Country | Fruit |
| ------- | ---------- |
| USA | Pineapple |
| USA | Apple |
| Canada | Watermelon |
| Canada | Banana |
| Canada | Apple |
| Mexico | Cherry |
| Mexico | Apple |
| Mexico | Apple |
| ... | ... |
Create example data:
import pandas as pd
import numpy as np
df = pd.DataFrame(
np.array([
['USA', 'USA', 'Canada', 'Canada', 'Canada', 'Canada', 'Canada', 'Mexico', 'Mexico', 'Mexico', 'Mexico', 'Brazil', 'Brazil', 'Brazil', 'Brazil', 'UK', 'UK', 'France', 'France', 'Germany', 'Germany', 'Germany', 'Germany', 'Germany', 'Italy', 'Italy', 'Spain', 'Spain', 'Spain', 'Spain', 'Spain'],
['Pineapple', 'Apple', 'Pineapple', 'Apple', 'Cherry', 'Watermelon', 'Orange', 'Apple', 'Banana', 'Cherry', 'Orange', 'Watermelon', 'Banana', 'Apple', 'Blueberry', 'Cherry', 'Apple', 'Banana', 'Blueberry', 'Banana', 'Apple', 'Cherry', 'Blueberry', 'Pineapple', 'Pineapple', 'Watermelon', 'Pineapple', 'Watermelon', 'Apple', 'Orange', 'Blueberry'],
]).T,
columns=['Country', 'Fruit'],
).set_index('Country')
df['other columns'] = '...'
Setup:
M = 10 # number of fruits to sample per country
rng = np.random.default_rng(seed=123) # set seed for reproducibility
# create weights for later use
fruit_weights = 1 / df.groupby('Fruit').size().rename('fruit_weights')
country_weights = 1 / df.groupby('Country').size().rename('country_weights')
# normalize weights to sum to 1
fruit_weights /= fruit_weights.sum()
country_weights /= country_weights.sum()
(1) Sample M fruits per country uniformly:
sampled_fruits = df.groupby('Country').sample(n=M, replace=True, random_state=rng)
(2) Sample M fruits per country inversely proportional to the number of occurrences of the fruit:
df2 = df.join(fruit_weights, on='Fruit') # add weights to a copy of the original dataframe
sampled_fruits = df2.groupby('Country').sample(
n=M,
replace=True,
random_state=rng,
weights='fruit_weights',
)
(3) Sample M fruits per country (on average) uniformly, but bootstrap the countries:
sampled_fruits = pd.concat(
{
s: df.sample(
n=df.index.nunique(), # number of countries
weights=country_weights,
replace=True,
random_state=rng,
)
for s in range(M)
},
names=['sample', 'Country'],
).reset_index('sample')
(4) Sample M fruits per country (on average) inversely proportional to the number of occurrences of the fruit, but bootstrap the countries:
df4 = df.join(fruit_weights, on='Fruit')
# normalize fruit weights to sum to 1 per country to not affect the country weights
df4['fruit_weights'] = df4.fruit_weights.groupby('Country').transform(lambda x: x / x.sum())
df4 = df4.join(country_weights, on='Country')
weight_cols = [c for c in df4.columns if '_weights' in c]
weights = df4[weight_cols].prod(axis=1)
df4 = df4.drop(columns=weight_cols)
sampled_fruits = pd.concat(
{
s: df4.sample(
n=df.index.nunique(), # number of countries
weights=weights,
replace=True,
random_state=rng,
)
for s in range(M)
},
names=['sample', 'Country'],
).reset_index('sample')
Number (4) almost accomplishes what I want. The countries and fruits are sampled independently uniformly at random.
There is only one issue:
Assume now that I also want to sample vegetables and then (somehow) compare the results to the results from the fruits. Assume that the countries remain the same, but the number of different vegetables is not equal to the number of different fruits, neither overall, nor for a given country (at least not for all countries).
This will result in different sets of countries being sampled for fruits and vegetables for any given bootstrap iteration 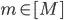 . To clarify, for each bootstrap iteration , the sampled
. To clarify, for each bootstrap iteration , the sampled countries should be identical for fruits and vegetables, i.e.
for m in range(M):
assert all(sampled_fruits[sampled_fruits['sample'] == m].index == sampled_vegetables[sampled_vegetables['sample'] == m].index)
(I know how to achieve the result I want using nested for-loops, sampling a country followed by a fruit/vegetable, but this is something I want to avoid.)
(The fruits and vegetables are just random things chosen to illustrate my question. In my real use case, the countries are samples in a test set, and the fruits and vegetables are two different groups of humans, where each human has assessed / made predictions on a subset of the test set.)