Exact Method
A precise way is to use tiktoken, which is a python library. Taken from the openAI cookbook:
import tiktoken
encoding = tiktoken.encoding_for_model("gpt-3.5-turbo")
num_tokens = len(encoding.encode("Look at all them pretty tokens"))
print(num_tokens)
More generally, you can use
encoding = tiktoken.get_encoding("cl100k_base")
where cl100k_base is used in gpt-4, gpt-3.5-turbo, text-embedding-ada-002;
p50k_base is used in Codex models, text-davinci-002, text-davinci-003; and r50k_base is what's used in gpt2, and GPT-3 models like davinci. r50k_base and p50k_base and often (but not always) gives the same results.
Approximation Method
You usually just want you program to not crash due to exceeding the token limit, and just need a character count cutoff such that you won't exceed the token limit. Testing with tiktoken reveals that token count is usually linear, particularly with newer models, and that 1/e seems to be a robust conservative constant of proportionality. So, we can write a trivial equation for conservatively relating tokens to characters:
'#tokens <? #characters * (1/e) + safety_margin'
where <? means this is very likely true, and 1/e = 0.36787944117144232159552377016146.
an adaquate choice for safety_margin seems to be 2. In some cases when using with r50k_base this needed to be 8 after 2000 characters. There are two cases where the safety margin comes into play: first for very low character count; there a value of 2 is enough and needed for all models. Second is if the model fails to reason about what it's looking at, resulting in a wobbly/noisy relationship between character count and # tokens with a constant of proportionality closer to 1/e, that may meander over the 1/e limit.
Main Approximation Result
Now reverse this to get a maximum number of characters to fit within a token limit:
'max_characters = (#tokens_limit - safety_margin) * e'
where e = 2.7182818284590... Now you've got an instant, language and platform independent, and dependency-free solution for not exceeding the token limit.
Show Your Work
With a paragraph of English
For model cl100k_base with English text, #tokens = #chars0.2016568976249748 + -5.277472848558375
For model p50k_base with English text, #tokens = #chars0.20820463015644564 + -4.697668008159241
For model r50k_base with English text, #tokens = #chars*0.20820463015644564 + -4.697668008159241
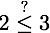
With a paragraph of Lorem ipsum
For model cl100k_base with Lorem ipsum, #tokens = #chars0.325712437966849 + -5.186204883743613
For model p50k_base with Lorem ipsum, #tokens = #chars0.3622005352481815 + 2.4256199405020595
For model r50k_base with Lorem ipsum, #tokens = #chars*0.3622005352481815 + 2.4256199405020595

With a paragraph of python code:
For model cl100k_base with sampletext2, #tokens = #chars0.2658446137873485 + -0.9057612056294033
For model p50k_base with sampletext2, #tokens = #chars0.3240730228908291 + -5.740016444496973
For model r50k_base with sampletext2, #tokens = #chars*0.3754121847018643 + -19.96012603693265