Without the ability to use recursive CTEs or cross apply, splitting rows based on a string field in Spark SQL becomes more difficult.
The explode function in Spark SQL can be used to split an array or map column into multiple rows.
While it do not work directly with strings, you will have to first split the string column into an array using the split function and then apply the explode function to the resulting array column.
Using the posexplode function
Similar to explode, the posexplode function can be used to split an array or map column into multiple rows, but it also includes the position of each value in the array.
This function can be used to split a string column by treating it as an array of characters.
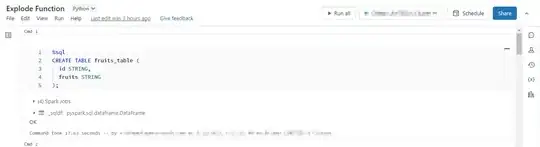
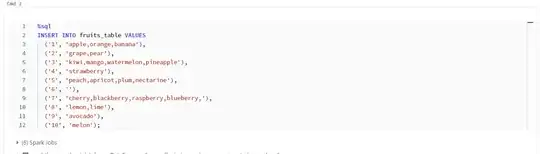
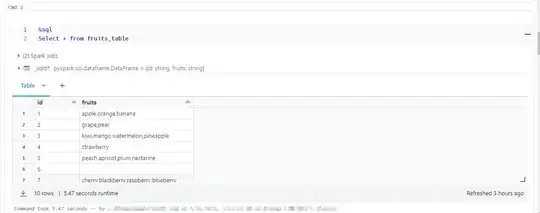
For example I have created a data frame and a SQL table I have provided both the approaches
 You have 2 approaches
Using the explode function:
Using the posexplode function:
You have 2 approaches
Using the explode function:
Using the posexplode function:
The above both approaches will work in SQL and Pyspark.
Explode Function:
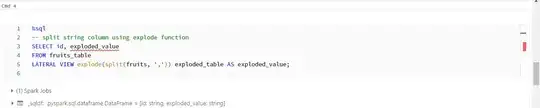
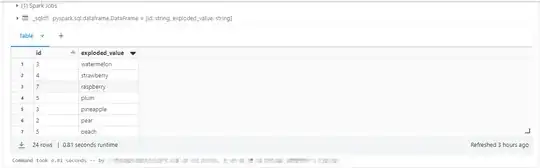
%sql
-- split string column using explode function
SELECT id, exploded_value
FROM fruits_table
LATERAL VIEW explode(split(fruits, ',')) exploded_table AS exploded_value;
 posexplode function:
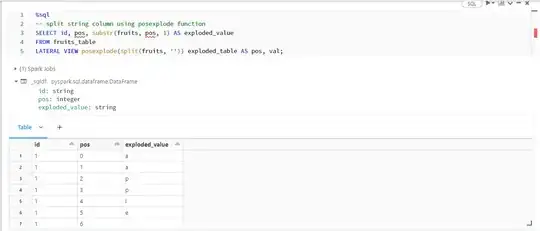
posexplode function:
%sql
-- split string column using posexplode function
SELECT id, pos, substr(fruits, pos, 1) AS exploded_value
FROM fruits_table
LATERAL VIEW posexplode(split(fruits, '')) exploded_table AS pos, val;
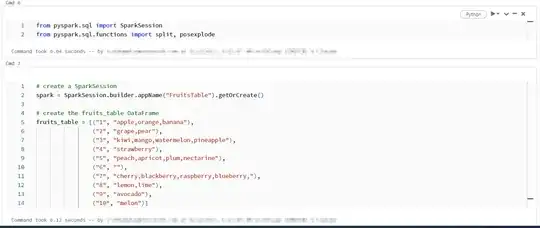
In Pyspark you will have to import the functions like below
from pyspark.sql import SparkSession
from pyspark.sql.functions import split, posexplode
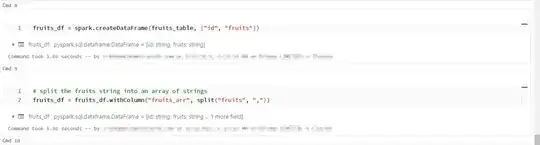
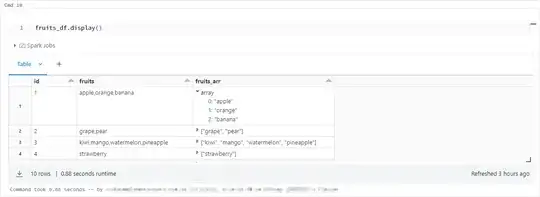
split the fruits string into an array of strings
Using a new column as fruits_arr
fruits_df = fruits_df.withColumn("fruits_arr", split("fruits", ","))
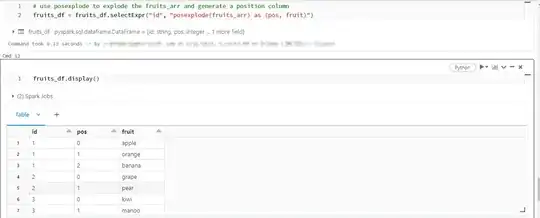
 use posexplode to explode the fruits_arr and generate a position column
use posexplode to explode the fruits_arr and generate a position column
fruits_df = fruits_df.selectExpr("id", "posexplode(fruits_arr) as (pos, fruit)")