As far as my understanding you can build your Synapse Pipeline
Based on the metadata of the files existing in the ADLS Gen 2.
In my experience I have delt with the CSV file to dynamically copy the file to Azure synapse dedicated pool.
Rather than hardcoding or Copying individual file to each table. This approach may help you.
For example I have 2 csv files in ADLS
EMPLOYEE.CSV and DEPARTMENTS.CSV
First I Do the manual import schema to get the json body for the columns only that I need(For desired columns only).
 from the above Json you can get the TYPE key and Mapping key.
which will point source and sink Column name. samefor the employee dataset. copy the Json body into a notepad.
Now In the Azure synapse I am creating a config table called
Table_Mapping. with below schema.
from the above Json you can get the TYPE key and Mapping key.
which will point source and sink Column name. samefor the employee dataset. copy the Json body into a notepad.
Now In the Azure synapse I am creating a config table called
Table_Mapping. with below schema.
Create table table_mapping
(
SourceFile Nvarchar(50),
SourceTableSchema NVARCHAR(50),
SinkaTableName NVARCHAR(50),
jsonMapping NVARCHAR(4000)
)
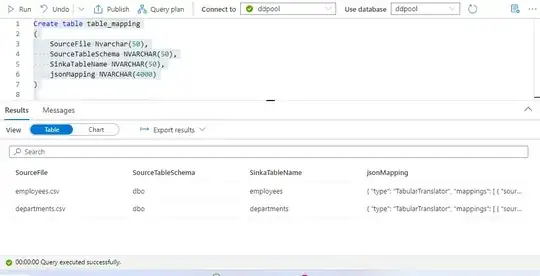 The Json Mapping column consist of the above json body of the Desired columns only.
Now Lets Build Dynamic Pipeline.
Get metadata activity To know what file we have in ADLS it should point only folder NOT TO any file.
The Json Mapping column consist of the above json body of the Desired columns only.
Now Lets Build Dynamic Pipeline.
Get metadata activity To know what file we have in ADLS it should point only folder NOT TO any file.
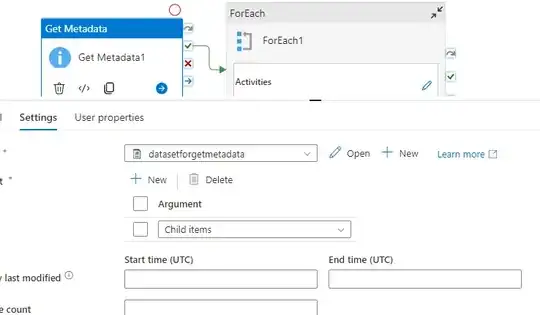 For Each
For Each
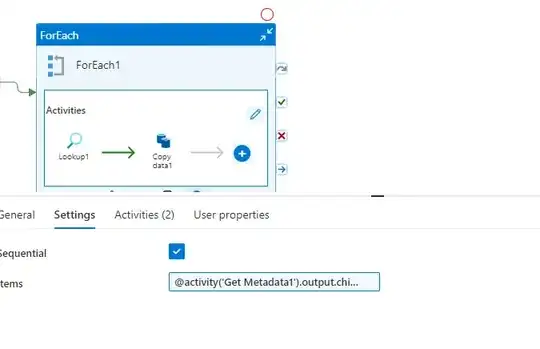
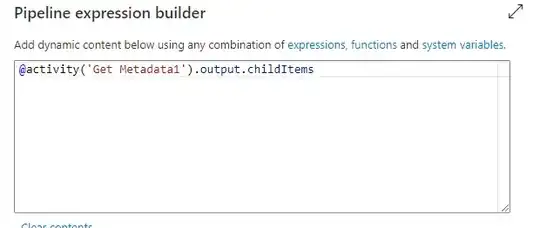 Inside FOR EACH LOOK UP
In Look up we have the TABLE_Mapping so for each Iteration it will take the file name and table name and so on.
Inside FOR EACH LOOK UP
In Look up we have the TABLE_Mapping so for each Iteration it will take the file name and table name and so on.
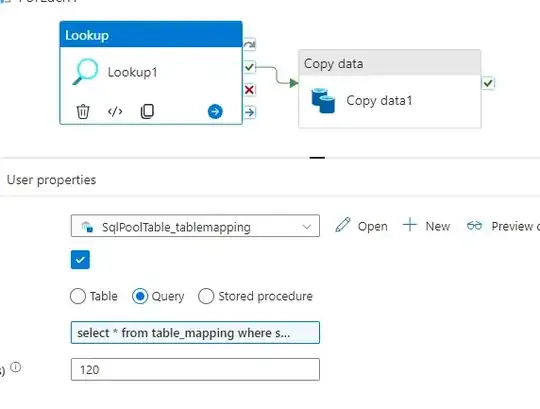 In the Query
In the Query
select * from table_mapping where sourceFile='@{item().name}'
Next Copy activity Create Data set parameters for both Source and sink
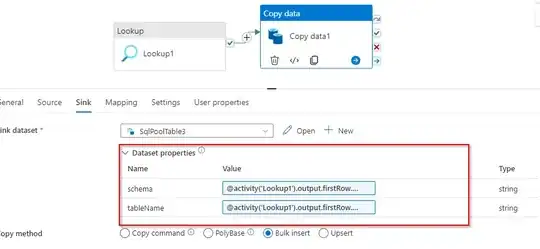 here is the Expression for the Source and Sink dataset parameters
Source dataset:
here is the Expression for the Source and Sink dataset parameters
Source dataset:
FileName: @activity('Lookup1').output.firstRow.SourceFile
Sink dataset:
Schema:
@activity('Lookup1').output.firstRow.SourceTableSchema
tabelName:
@activity('Lookup1').output.firstRow.SinkaTableName
In the Mapping ADD DYNAMIC CONTENT with below expression.
@json(activity('Lookup1').output.firstRow.jsonMapping)
This approach of having a configuration Table for the columns can dynamically copy the data from source(ADLS) to Sink(Synapse dedicated SQL).