- You need to use a combination of derived column transformation, sort transformation and an aggregate transformation to get the desired result. The following is the starting data that I have:
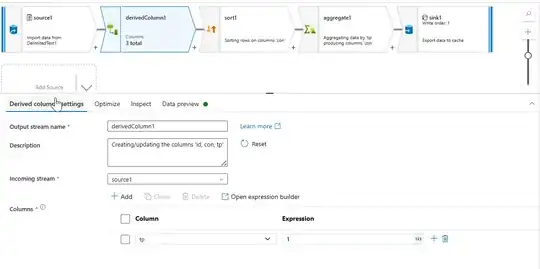
- I have added a new column
tp with a static value 1. This can be used to group the data as required.
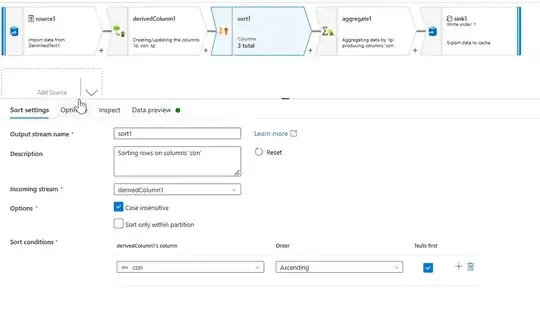
- Now sort the data on the required column using sort transformation with configurations similar to the ones shown below;
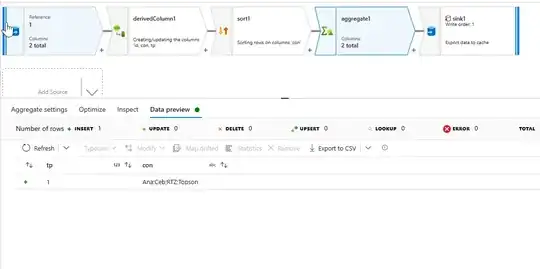
- Now using the aggregate transformations, to group by the
tp column. In the aggregates tab, use the required column with the following expression to get the desired results.
left(substring(toString(reduce(collect(con), '', #acc+';'+#item, #result)),2),100)
- The following is the entire Dataflow JSON:
{
"name": "dataflow1",
"properties": {
"type": "MappingDataFlow",
"typeProperties": {
"sources": [
{
"dataset": {
"referenceName": "DelimitedText1",
"type": "DatasetReference"
},
"name": "source1"
}
],
"sinks": [
{
"name": "sink1"
}
],
"transformations": [
{
"name": "derivedColumn1"
},
{
"name": "sort1"
},
{
"name": "aggregate1"
}
],
"scriptLines": [
"source(output(",
" id as short,",
" con as string",
" ),",
" allowSchemaDrift: true,",
" validateSchema: false,",
" ignoreNoFilesFound: false) ~> source1",
"source1 derive(tp = 1) ~> derivedColumn1",
"derivedColumn1 sort(asc(con, true),",
" caseInsensitive: true) ~> sort1",
"sort1 aggregate(groupBy(tp),",
" con = left(substring(toString(reduce(collect(con), '', #acc+';'+#item, #result)),2),100)) ~> aggregate1",
"aggregate1 sink(validateSchema: false,",
" skipDuplicateMapInputs: true,",
" skipDuplicateMapOutputs: true,",
" store: 'cache',",
" format: 'inline',",
" output: false,",
" saveOrder: 1) ~> sink1"
]
}
}
}