Below is a working code, where

- I read lists of csv files from 9 different folders
 2. Make each folder a list.
2. Make each folder a list.
Rename elements of a list (drop '.csv' and others).
Join within each folder to make 1 big dataframe.
Merge all 9 dataframes to make 1 dataframe.
Get follow up RIDs and loss-to-follow-up RIDs and their rates.
- From as1 to as3, there are AS{n}_AREA columns and from as4 to as9 there are AS{n}_DATA_CLASS columns For MRE,
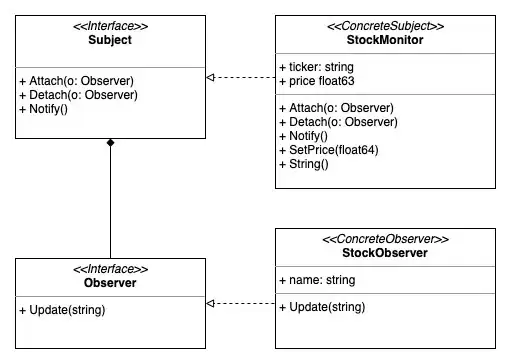


I have used ideas given here mostly, but when I add them up, the code somehow looks redundant and more could be done to look tidy to others.
Any ideas please? Thank you!
library(dplyr); library(plyr)
library(magrittr); library(stringr)
library(ExclusionTable)
library(lubridate)
library(tidyverse); library(tidyr)
library(janitor)
library(survival)
library(ggsurvfit); library(gtsummary)
library(zoo)
library(tidycmprsk)
# AA cohort (2 of 3)
## as
i=1
num_fu = c(1,2,3,4,5,6,7,8,9)
as <- data.frame()
df <- data.frame()
dfs <- data.frame()
data_dir <- 'C:/Users/thepr/Documents/data/as'
assign(paste0("flnames", i), list.files(path = paste0(data_dir, i), pattern = "\\.csv", full.names = TRUE))
assign(paste0("as", i, "_list"), lapply(get(paste0("flnames", i)),
function(x){base::as.data.frame(read.csv(x))}))
nm <- gsub(".csv", "", basename(eval(parse(text = paste0("flnames", i))))) %>% str_sub(., 1,6)
assign(paste0("as", i, "_list"), setNames(get(paste0("as", i, "_list")), nm))
df <- Reduce(full_join, get(paste0("as", i, "_list")))
assign(paste0("as",i), df[!duplicated(base::as.list(df))])
dfs <- df
for (i in 2:length(num_fu)){
RID_common <- as1$RID %in% get(paste0("as", i))$RID
assign(paste0("flnames", i), list.files(path = paste0(data_dir, i), pattern = "\\.csv", full.names = TRUE))
assign(paste0("as", i, "_list"), lapply(get(paste0("flnames", i)),
function(x){base::as.data.frame(read.csv(x))}))
nm <- gsub(".csv", "", basename(eval(parse(text = paste0("flnames", i))))) %>% str_sub(., 1,6)
assign(paste0("as", i, "_list"), setNames(get(paste0("as", i, "_list")), nm))
df <- Reduce(full_join, get(paste0("as", i, "_list")))
assign(paste0("as",i), df[!duplicated(base::as.list(df))])
dfs <- merge(dfs, df, by = "RID", all.x = TRUE)
dfs <- dfs[!duplicated(base::as.list(dfs))]
if(paste0("AS", i, "_AREA") %in% colnames(get(paste0("as", i)))){
assign(paste0("fu_",i-1), get(paste0("as", i))[RID_common, c("RID", paste0("AS", i, "_AREA"))])
assign(paste0("fu_loss_",i-1), get(paste0("as", i))[!RID_common, c("RID", paste0("AS", i, "_AREA"))])
# FU rate
assign(paste0("fu_rate_", i-1), nrow(get(paste0("as", i)))/nrow(as1))
}
else if(paste0("AS", i, "_DATA_CLASS") %in% colnames(get(paste0("as", i)))){
assign(paste0("fu_",i-1), get(paste0("as", i))[RID_common, c("RID", paste0("AS", i, "_DATA_CLASS"))])
assign(paste0("fu_loss_",i-1), get(paste0("as", i))[!RID_common, c("RID", paste0("AS", i, "_DATA_CLASS"))])
# FU rate
assign(paste0("fu_rate_", i-1), nrow(get(paste0("as", i)))/nrow(as1))
}
else{}
}