TLDR: Output results show no prediction potential.
I want to predict the next element of a sequence of categorical data. In this context, the neural network should determine what is the most likely next element in a sequence based on the sequence itself.
I have 3 classes, therefore a completely random prediction would be 1/3 chance of success. The results I got until now are close to 1/3, so the neural network process did not improve random choices. I tried using a fixed pattern that repeats, which should be obvious to the process, but it does not seems to be able to track patterns at all. I mean, I am new to the neural networks methods for prediction, so I'm not sure if fixed patterns are obvious for neural networks.
Regarding the inputs, what I have tried: (1) x inputs are the indexes of this sequence (let's say this sequence has N elements) and y inputs are the elements (N samples); (2) x input is a vector with the sequence elements, except the last term and y input is a vector with the sequence element, except the first element (1 sample); and (3) x inputs are vectors with increasing elements from the sequence, i.e., x1 carries only the first element, x2 carries the two initial elements and so on. Regarding y inputs, it is the consecutive element of each x input, resulting in a vector with all the sequence elements, except the first.
The code using inputs (3) is shown below: UPDATED
import numpy as np
import pandas as pd
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras.preprocessing.sequence import pad_sequences
data = ["A", "B", "C", "A", "B", "C", "A", "B", "C", "A", "B", "C", "A", "B", "C"]
prev_history = []
correct_guess = 0
for i in range(1,100):
input_size = len(data)
vocab = ["A", "B", "C"]
layer = keras.layers.StringLookup(vocabulary=vocab)
x_train = np.array(layer(data))
x_train = x_train - 1
x_sequences = []
y_sequences = []
for i in range(1, input_size):
x_sequences.append(x_train[:i])
y_sequences.append(x_train[i])
x_sequences[-1] = np.concatenate((x_sequences[-1], [-1]), axis=0)
x_train = keras.utils.pad_sequences(x_sequences, padding='post', value=-1)
y_train = np.array(y_sequences).transpose()
model = keras.Sequential([
keras.layers.Dense(8, activation='relu', input_dim=input_size),
keras.layers.Dense(8, activation='relu'),
keras.layers.Dense(3, activation='softmax')
])
model.compile(loss='sparse_categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
model.fit(x_train, y_train, epochs=1, batch_size=1, shuffle=False)
if prev_history != []:
if data[-1] == prev_history[-1]:
correct_guess += 1
if len(prev_history) > 0:
correct_guess_rate = correct_guess/(len(prev_history))
x_pred = np.array(layer(data))
x_pred = x_pred - 1
x_pred = x_pred.reshape(1, input_size)
predchance = model.predict(x_pred)
max_n = np.argmax(predchance)
pred = layer.get_vocabulary()[max_n+1]
prev_history.append(pred)
choices = ["A", "B", "C"]
data.append(choices[input_size % len(choices)])
I was expecting to get results better at least than 1/3 of successfully predictions. I tried increasing the sequence, increasing layers, increasing layer units, increasing epochs, changing model... I also must confess I am not sure about the input configuration and batch_size, as I had a hard time setting the code to work without errors. Well, I have tried to find similar problems with solution and learn more to find what I am doing wrong, but I considered to post here.
Any tips or point to possible errors?
Update
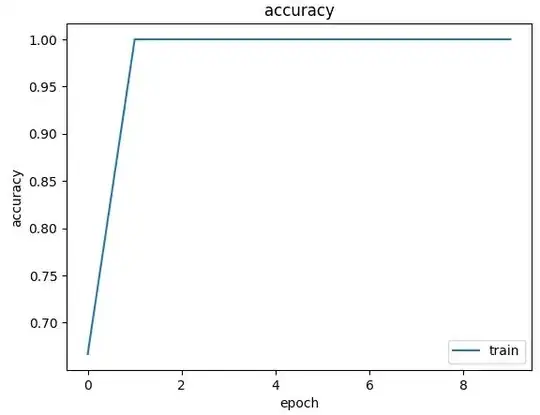
I appreciate replies from community members. I have learned a lot from this simple project. The previous sample sequences weren't adequate for the objective, therefore I used sequences of combinations of three elements as data input with their consecutive element as targets. With this modification, the resulting code is:
import numpy as np
import pandas as pd
import tensorflow as tf
from tensorflow import keras
data = ["A", "B", "C", "A", "B", "C", "A", "B", "C", "A", "B", "C", "A", "B", "C", "A", "B", "C", "A", "B", "C"]
prev_history = []
correct_guess = 0
for i in range(1,100):
input_size = len(data)
vocab = ["A", "B", "C"]
layer = keras.layers.StringLookup(vocabulary=vocab)
data_u = layer(data)
data_u = data_u - 1
seq_length = 3
dataset = keras.utils.timeseries_dataset_from_array(
data_u.numpy(),
targets = data_u[seq_length:],
sequence_length = seq_length,
batch_size = 2
)
model = keras.Sequential([
keras.layers.SimpleRNN(32, activation='relu', input_shape=[None,1]),
keras.layers.Dense(3, activation='softmax')
])
model.compile(loss='sparse_categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
model.fit(dataset, epochs=10, shuffle=True)
if prev_history != []:
if data[-1] == prev_history[-1]:
correct_guess += 1
if len(prev_history) > 0:
correct_guess_rate = correct_guess/(len(prev_history))
x_pred = data_u[-seq_length:]
x_pred = tf.reshape(x_pred, [1,seq_length])
predchance = model.predict(x_pred)
max_n = np.argmax(predchance)
pred = layer.get_vocabulary()[max_n+1]
prev_history.append(pred)
choices = ["A", "B", "C"]
data.append(choices[input_size % len(choices)])
With this code, the predictions were very accurate. I tried different patterns, and the predictions are consistently superior to random choices.