Here another array solution approach, i.e. it spills the entire result all at once (formula 1):
=LET(A,A1:A12, B,B1:B12, n,ROWS(A), seq,SEQUENCE(n),
MAP(seq, LAMBDA(s,IF(INDEX(A,s)=1,LET(end, @FILTER(seq, (seq>s) * (A=1),n+1),
SUM(FILTER(B, (seq>=s) * (seq<end)))),""))))
or you can use this alternative (formula 2). The previous formula has a little overhead calculation, because we need to get just the first element of the first FILTER call, but we get the entire FILTER output. The following formula avoids that.
=LET(A,A1:A12, B,B1:B12, n,ROWS(A), seq,SEQUENCE(n), idx,IF(A=1,seq,0),
MAP(idx, LAMBDA(x, IF(x=0,"", SUM(FILTER(B, (seq>=x)
* (seq<XLOOKUP(x+1,idx,idx,n+1,1))))))))
Here is the output for formula 1:
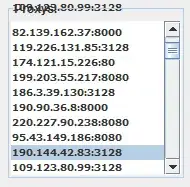
In formula 1 it iterates via MAP over all index positions of the input (seq). On each iteration (s) it checks for the given index s if the column A values (A) is equal to 1 via INDEX. If that is the case (otherwise it returns an empty string), it finds the index position (end) of the next 1 value for index position greater than the current iteration value (s) via FILTER function. Since we are only interested in the first value (index position of the next 1 value) of the FILTER output we use Implicit intersection operator: @. If the condition doesn't match, then we use the third input argument of FILTER to return n+1, where n is the number of rows of the input data.
Since end represents the index position of the next 1 value or the number of rows plus one in case no more 1 value were found, now we can use FILTER again to select B column values (B)
from s to end-1 index positions and sum it.
In formula 2 it identifies first the index positions where A is equal to 1 (idx), otherwise returns 0. By definition non zero values of idx are in ascending order. To identify the end of the interval (position of the following 1 value in A), it uses XLOOKUP with approximate search (1-equal or greater) to look for the next element of x, i.e. x+1. It returns the position of the next 1 value in A, otherwise the n+1. Therefore the range of the B to sum is filtered for the index positions seq between x and the output of XLOOKUP.
Performance Analysis
Here a summary based on different scenarios to measure the performance of different answers provided to this question. I am considering the following scenarios:
- A: worse case scenario, 1 in the first row and the rest with zeros
- B: Random set for column A, with significant more
0s than 1s
- C: Random set for column A, with uniform distribution for
1s and 0s.
In all cases I am considering an input of 7000 rows.
To generate a non-uniform [0,1]-distribution I use the following:
=LET(rnd, RANDARRAY(10000,1,1,10,1),IF(rnd=1,1,0))
I am considering the following solutions:
- Provided by: @VBasic2008 with the correction indicated in the comment section of his answer.
- Provided by: @MayukhBhattacharya. This solution uses
MMULT, but it works for more than 7500 rows.
- Provided by: @P.b (initial approach, not the approach provided in the comment section, which doesn't provide a correct result). Worth to notice that this solution stops working around
7500 rows.
- Provided by @DavidLeal formula 2 using
XLOOKUP. The formula 1 was inefficient, so it was not considered in the analysis.
Here are the results for Excel Desktop:
| Scenario |
MayukhBhattacharya |
VBasic2008 |
DavidLeal |
P.b |
| A |
10ms |
1,070ms |
10ms |
7,300ms |
| B |
560ms |
1,310ms |
970ms |
7,710ms |
| C |
2,640ms |
2,270ms |
4,780ms |
7,590ms |
I would say the solution provided by @MayukhBhattacharya is the best one in all scenarios tested, then the solution provided by @VBasic2008, it works pretty well, but it fails for the worse case scenario (A) taking significant time.
It brought my attention that running the same test under Excel for Web (free version). I don't get the same results. Again MayukhBhattacharya and VBasic2008 are the best solutions, but this time the solution provided by VBasic2008 performs better:
| Scenario |
MayukhBhattacharya |
VBasic2008 |
DavidLeal |
P.b |
| A |
0ms |
0ms |
10ms |
9,950ms |
| B |
770ms |
40ms |
1,570ms |
10,080ms |
| C |
3,640ms |
850ms |
9,930ms |
10,440ms |
I tested also @JvdV, provided in the comment section of P.b solution, which is at the end a variation of @MayukhBhattacharya approach. @JvdV is more efficient than @P.b solution, but worse than @MayukhBhattacharya solution.
Worth to mention that @MayukhBhattacharya solution can be optimized because the input argument lookup_array from XMATCH is sorted in ascending order, so we can use a binary search in XMATCH using the input argument search_mode=2. Which provides an improvement around 9%. The same optimization applies to @VBasic2008 solution, since it uses XMATCH with lookup_array in ascending order.
Here is the link to the Excel file used for doing the performance analysis. The summary of the result is on the first tab. Be aware the file has the following configuration: Formulas -> Calculation Options->Manual, to avoid any specific calculation interfere other results. It uses volatile Excel functions (RANDARRAY, NOW) so it avoids automatic recalculation.
It would be interesting to verify the results by others.
Conclusion
Using the idea of finding start/end for each group, used by @VBasic2008 and by @DavidLeal. Using INDEX performs better than FILTER. For example @DavidLeal solution modified to remove FILTER as follows has a similar performance as @VBasic2008 solution, but not better:
= LET(A,A1:A12, B,B1:B12, n,ROWS(A), seq,SEQUENCE(n), idx,
IF(A=1,seq,0), MAP(idx, LAMBDA(x, IF(x=0,"",
LET(xe, XLOOKUP(x+1,idx,idx,n+1,1)-1,SUM(INDEX(B, SEQUENCE(xe-x+1,,x))))))))
@VBasic2008 solution has a simple way to find start/end of the intervals, compared to the previous formula, therefore the performance is better.
Solutions using MMULT to identify each group, work better when the calculation involves a reduced portion such as in @MayukhBhattacharya solution, compared to @P.b solution. Which is also good to avoid any possible Excel limits.
Both approaches are good strategy, taking into account previous considerations.
Still an open question, why some scenarios work better depending on Excel platform (Desktop, Web) used. Probably internally the functions are not implemented in the same way, or different version for the same functions used.









