I have simple txt file indexed in pine cone, and question answering works perfectly fine without memory.
When I add ConversationBufferMemory and ConversationalRetrievalChain using session state the 2nd question is not taking into account the previous conversation.
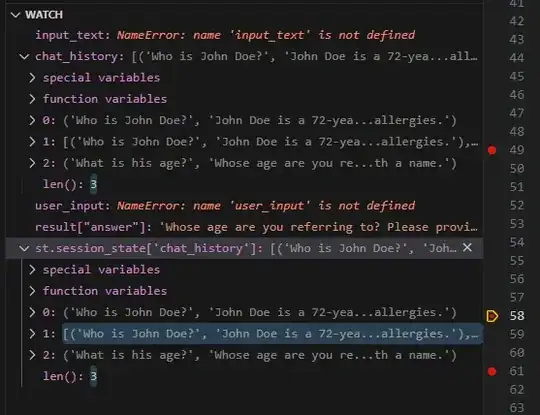
1st Question: Who is John Doe? He is a male, 70 years old, etc,etc 2nd Question. How old is he? To who are you referring to?
But chat history looks like this:
MY code looks like this, what am I missing?
import streamlit as st
import openai
import os
import pinecone
import streamlit as st
from dotenv import load_dotenv
from langchain.chains.question_answering import load_qa_chain
from dotenv import load_dotenv
from langchain.chat_models import AzureChatOpenAI
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.vectorstores import Pinecone
import streamlit as st
from streamlit_chat import message
from langchain.memory import ConversationBufferMemory
from langchain.prompts import PromptTemplate
from langchain.chains import ConversationChain
from langchain.chains import ConversationalRetrievalChain
#load environment variables
load_dotenv()
OPENAI_API_KEY = os.getenv("OPENAI_API_KEY")
OPENAI_DEPLOYMENT_ENDPOINT = os.getenv("OPENAI_DEPLOYMENT_ENDPOINT")
OPENAI_DEPLOYMENT_NAME = os.getenv("OPENAI_DEPLOYMENT_NAME")
OPENAI_MODEL_NAME = os.getenv("OPENAI_MODEL_NAME")
OPENAI_EMBEDDING_DEPLOYMENT_NAME = os.getenv("OPENAI_EMBEDDING_DEPLOYMENT_NAME")
OPENAI_EMBEDDING_MODEL_NAME = os.getenv("OPENAI_EMBEDDING_MODEL_NAME")
OPENAI_API_VERSION = os.getenv("OPENAI_API_VERSION")
OPENAI_API_TYPE = os.getenv("OPENAI_API_TYPE")
#pinecone
PINECONE_API_KEY = os.getenv("PINECONE_API_KEY")
PINECONE_ENV = os.getenv("PINECONE_ENV")
#init Azure OpenAI
openai.api_type = OPENAI_API_TYPE
openai.api_version = OPENAI_API_VERSION
openai.api_base = OPENAI_DEPLOYMENT_ENDPOINT
openai.api_key = OPENAI_API_KEY
st.set_page_config(
page_title="Streamlit Chat - Demo",
page_icon=":robot:"
)
chat_history = []
def get_text():
input_text = st.text_input("You: ","Who is John Doe?", key="input")
return input_text
def query(payload, chain,query,chat_history ):
result = chain({"question": query, "chat_history": chat_history})
chat_history.append((query, result["answer"]))
thisdict = {
"generated_text": result['answer']
}
return thisdict, chat_history
def main():
st.title('Scenario 2: Question Aswering on documents with langchain, pinecone and openai')
st.markdown(
"""
This scenario shows how to chat wih a txt file which was indexed in pinecone.
"""
)
pinecone.init(
api_key=PINECONE_API_KEY, # find at app.pinecone.io
environment=PINECONE_ENV # next to api key in console
)
if 'generated' not in st.session_state:
st.session_state['generated'] = []
if 'past' not in st.session_state:
st.session_state['past'] = []
if 'chat_history' not in st.session_state:
st.session_state['chat_history'] = []
index_name = "default"
embed = OpenAIEmbeddings(deployment=OPENAI_EMBEDDING_DEPLOYMENT_NAME, model=OPENAI_EMBEDDING_MODEL_NAME, chunk_size=1)
retriever = Pinecone.from_existing_index(index_name, embed)
user_input = get_text()
llm = AzureChatOpenAI(
openai_api_base=OPENAI_DEPLOYMENT_ENDPOINT,
openai_api_version=OPENAI_API_VERSION ,
deployment_name=OPENAI_DEPLOYMENT_NAME,
openai_api_key=OPENAI_API_KEY,
openai_api_type = OPENAI_API_TYPE ,
model_name=OPENAI_MODEL_NAME,
temperature=0)
memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True)
chain = ConversationalRetrievalChain.from_llm(llm, retriever.as_retriever(), memory=memory)
if user_input:
output, chat_history = query({
"inputs": {
"past_user_inputs": st.session_state.past,
"generated_responses": st.session_state.generated,
"text": user_input,
},"parameters": {"repetition_penalty": 1.33}
},
chain=chain,
query=user_input,
chat_history=st.session_state["chat_history"])
st.session_state.past.append(user_input)
st.session_state.generated.append(output["generated_text"])
st.session_state.chat_history.append(chat_history)
if st.session_state['generated']:
for i in range(len(st.session_state['generated'])-1, -1, -1):
message(st.session_state["generated"][i], key=str(i))
message(st.session_state['past'][i], is_user=True, key=str(i) + '_user')
if __name__ == "__main__":
main()