- I have used the following xml data as my source for demonstration:
<payload>
<header>
<customerID>1234</customerID>
<createdDate>1/2/2023T15:33:22</createdDate>
</header>
<body>
<compartments>
<compartment>
<compartmentNo>1</compartmentNo>
<product>2</product>
<references>
<reference>
<referenceType>ShipmentID</referenceType>
<referenceValue>23434</referenceValue>
</reference>
</references>
</compartment>
<compartment>
<compartmentNo>2</compartmentNo>
<product>22</product>
<references>
<reference>
<referenceType>ShipmentID</referenceType>
<referenceValue>123434</referenceValue>
</reference>
</references>
</compartment>
</compartments>
</body>
</payload>
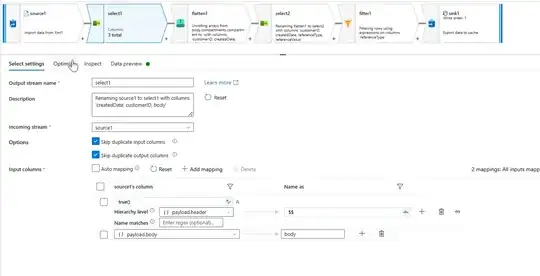
- I have used select transformation with rule based mapping to unpack the header property and a fixed mapping to select body.
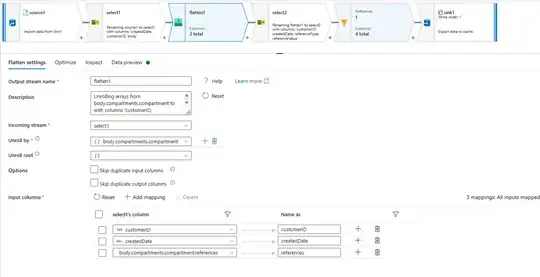
- I have used flatten transformation unrolling by
body.compartments.compartment with the following configurations.
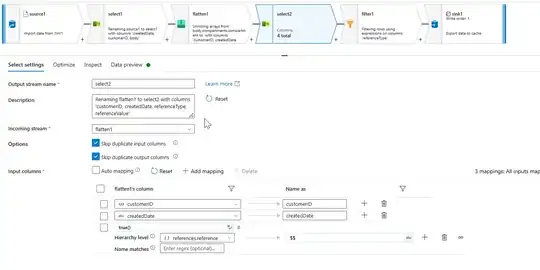
- I have used another select transformation to select only
customerID and createdDate as fixed mapping and a rule-based mapping to unpack the hierarchy references.reference:
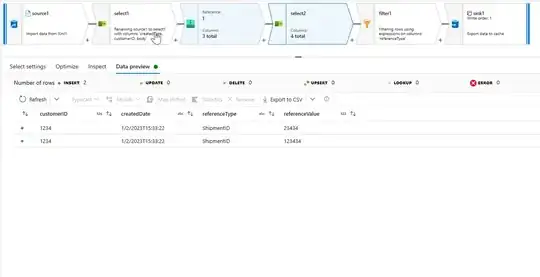
- The data preview after the above operations would be as shown in the below image:
- If you have other
referenceType values other than ShipmentID, you can use the filter transformation with condition referenceType=='ShipmentID'
- Now, you can select the sink table (shipments) and manually map the values to respective columns. The following is the entire dataflow JSON:
{
"name": "dataflow2",
"properties": {
"type": "MappingDataFlow",
"typeProperties": {
"sources": [
{
"dataset": {
"referenceName": "Xml1",
"type": "DatasetReference"
},
"name": "source1"
}
],
"sinks": [
{
"name": "sink1"
}
],
"transformations": [
{
"name": "select1"
},
{
"name": "flatten1"
},
{
"name": "select2"
},
{
"name": "filter1"
}
],
"scriptLines": [
"source(output(",
" payload as (body as (compartments as (compartment as (compartmentNo as short, product as short, references as (reference as (referenceType as string, referenceValue as integer)))[])), header as (createdDate as string, customerID as short))",
" ),",
" allowSchemaDrift: true,",
" validateSchema: false,",
" ignoreNoFilesFound: false,",
" validationMode: 'none',",
" namespaces: true) ~> source1",
"source1 select(mapColumn(",
" each(payload.header,match(true())),",
" body = payload.body",
" ),",
" skipDuplicateMapInputs: true,",
" skipDuplicateMapOutputs: true) ~> select1",
"select1 foldDown(unroll(body.compartments.compartment),",
" mapColumn(",
" customerID,",
" createdDate,",
" references = body.compartments.compartment.references",
" ),",
" skipDuplicateMapInputs: false,",
" skipDuplicateMapOutputs: false) ~> flatten1",
"flatten1 select(mapColumn(",
" customerID,",
" createdDate,",
" each(references.reference,match(true()))",
" ),",
" skipDuplicateMapInputs: true,",
" skipDuplicateMapOutputs: true) ~> select2",
"select2 filter(referenceType=='ShipmentID') ~> filter1",
"filter1 sink(validateSchema: false,",
" skipDuplicateMapInputs: true,",
" skipDuplicateMapOutputs: true,",
" store: 'cache',",
" format: 'inline',",
" output: false,",
" saveOrder: 1,",
" mapColumn(",
" customerID,",
" createdDate,",
" ShipmentID = referenceValue",
" )) ~> sink1"
]
}
}
}
