Apologies if there is a duplicate question. I couldn't find one.
This is in SQL Server (Azure Synapse)
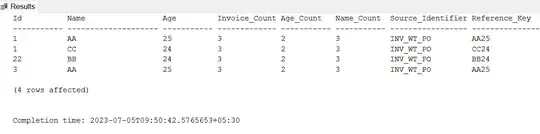
I have a table with 150+ columns and I am trying to get an aggregate COUNT( DISTINCT ) over a few of them.
Here is (a subset of) my query:
SELECT *
,count(DISTINCT XXX) AS Invoice_Count
,count(DISTINCT YYY) AS PO_Count
,count(DISTINCT ZZZ) AS PO_Item_Count
,'INV_WT_PO' AS Source_Identifier
,concat(XXX, YYY) AS Reference_Key
FROM [XXX].[YYY]
But I am getting the usual error:
XXX is invalid in the select list because it is not contained in either an aggregate function or the GROUP BY clause.
I understand the obvious solution would be to mention all the 150+ columns in the GROUP BY clause.
I did that and it worked but the performance is ABYSMAL. 1 minute 40 seconds vs. under 1 second for the query without the aggregate columns and GROUP BY clause.
I am curious if there is a better way to address this?
Thanks.