I have a ggplot2 plot such as the following:
mtcars %>%
group_by(gear, carb) %>%
summarise(
avg = mean(mpg),
n = n(),
gear = gear,
carb = carb
) %>%
ggplot(aes(
x = factor(gear),
y = avg,
color = carb,
group = carb
)) +
geom_point(position = "dodge")
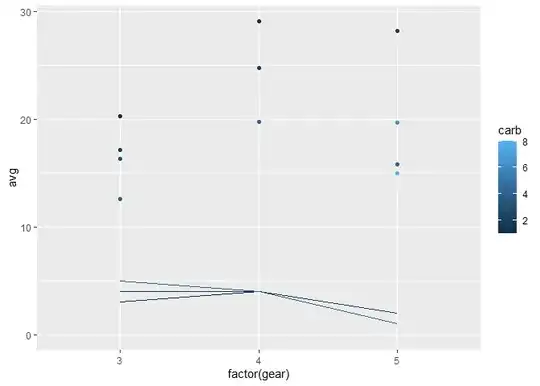
Which renders this:

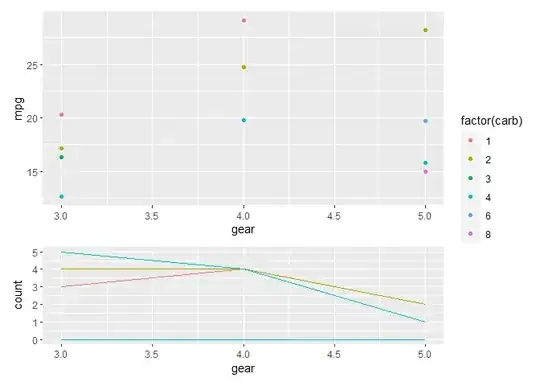
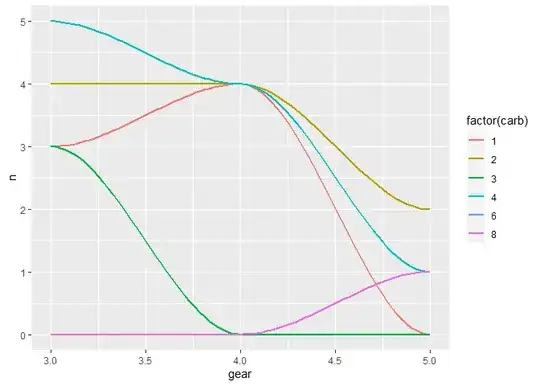
I now need to plot the density distribution of the three categories of the x axis (gear) using the value of n for the number of observations. I want this smooth distribution plot for n of each gear in each carb color.
I attempt to use the following:
mtcars %>%
group_by(gear,carb) %>%
summarise(
avg = mean(mpg),
n = n(),
gear=gear,
carb=carb
) %>%
ggplot(aes(
x=factor(gear),
y=avg,
color = carb,
group=carb)) +
geom_point(position = "dodge") +
geom_density(aes(x=factor(gear),y=n,color=carb))
But I receive the error:
Problem while setting up geom.
ℹ Error occurred in the 2nd layer.
Caused by error in `compute_geom_1()`:
! `geom_density()` requires the following missing aesthetics: x
Backtrace:
1. base (local) `<fn>`(x)
2. ggplot2:::print.ggplot(x)
4. ggplot2:::ggplot_build.ggplot(x)
5. ggplot2:::by_layer(...)
12. ggplot2 (local) f(l = layers[[i]], d = data[[i]])
13. l$compute_geom_1(d)
14. ggplot2 (local) compute_geom_1(..., self = self)
I have tried placing the variables inside aes() and outside, but nothing has allowed me to generate this plot. How can I generate distribution plots and add them to the larger other ggplot. I recognize I will have to rescale the value of n in order to fit the space below the points in the plot, but how can I set up the plot to accept the n as the variable of the count in the geom_density?