By documents , I mean each line item in the Azure Search Index
I need to frequently see what's present in my search index, modify/delete some line items from there. Have been trying to find python scripts/methods that can help me do this easily but seems like there is no straight forward way to this.
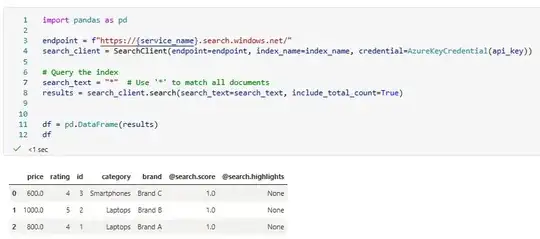
Ask : I basically want to export all rows/ some rows(based on filters on filterable fields) from the Search Index I already have in place. Just want to visualize everything in the index in a dataframe/json
I have already seen the below resources:
- SearchIndexClient Class documentation - no method to achieve this
- SearchClient Class documentation - no method to achieve this
- Export data from an Azure Cognitive Search index - Azure Samples - is not in Python
I have already looked into this answer from 2019, but it's too complicated as:
- it has variables like facet_value, facet_fields. The page size is being set to 1000 (is this a limitation?)
- what does page_size mean compared to the Document object that Azure Search Index calls each row in the index as
Any other answer on Stackoverflow doesn't really answer this..
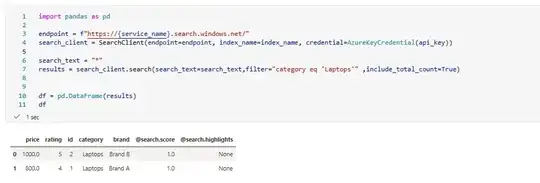
 With Filter:
With Filter: