I currently am facing an issue with loading CSV files directly from blob storage to our Azure SQL instance. I have the credentials correctly set up an able to access the files without any issue. However, when performing the BULK INSERT it fails at a certain row. I have tried the exact same file and the exact same BULK INSERT configuration on our local SQL server and it works without any issue.
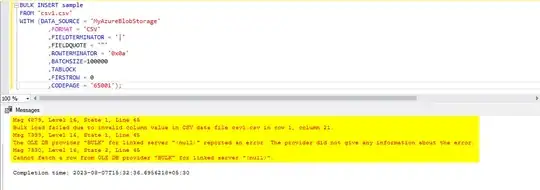
BULK INSERT dbo.this_is_a_table FROM
'transformed/this_is_a_csv.csv'
WITH (
DATA_SOURCE = 'this_is_a_blob_storage_data_source'
,FORMAT = 'CSV'
,FIELDTERMINATOR = '|'
,FIELDQUOTE = '"'
,ROWTERMINATOR = '0x0a'
,BATCHSIZE=100000
,TABLOCK
,FIRSTROW = 2
,CODEPAGE = '65001'
)
I have tried altering the FORMAT to DATAFILETYPE = 'char', tried rotating the ROWTERMINATORS, etc. without any luck so far.
The error is as follows:
Failed to execute query. Error: Bulk load failed due to invalid column value in CSV data file transformed/this_is_a_csv.csv in row 3128, column 10. The OLE DB provider "BULK" for linked server "(null)" reported an error. The provider did not give any information about the error.
Cannot fetch a row from OLE DB provider "BULK" for linked server "(null)".
Loading the data until MAXROW 3127 works perfectly fine. I checked the CSV file and there is nothing that stands out - basically identical to any other row in the file.
Any ideas or suggestions on what else I could try?
Sample data:
"MANDT"|"EBELN"|"BUKRS"|"BSTYP"|"BSART"|"BSAKZ"|"LOEKZ"|"STATU"|"AEDAT"|"ERNAM"|"LIFNR"|"EKORG"|"WAERS"|"BEDAT"|"FRGGR"|"FRGSX"|"FRGKE"|"FRGZU"|"FRGRL"|"ABSGR"|"PROCSTAT"
"100"|"4620739302"|"1000"|"F"|"UB"|""|""|"L"|"20230118"|"84HD937J3J392H371842CAZEF91374923HDTAZ32"|"0001000001"|"AB01"|"USD"|"20230118"|"A1"|"S1"|"F"|"XX"|""|"00"|"05"
"100"|"5729302783"|"1000"|"F"|"UB"|""|""|"L"|"20230118"|"84HD937J3J392H371842CAZEF91374923HDTAZ32"|"0001000002"|"AB01"|"USD"|"20230118"|"A1"|"S1"|"F"|"XX"|""|"00"|"05"
"100"|"5720562944"|"1000"|"F"|"UB"|""|""|"L"|"20230118"|"84HD937J3J392H371842CAZEF91374923HDTAZ32"|"0001000003"|"AB01"|"USD"|"20230118"|"A1"|"S1"|"F"|"XX"|""|"00"|"05"
"100"|"8401817494"|"1000"|"F"|"UB"|""|""|"L"|"20230118"|"84HD937J3J392H371842CAZEF91374923HDTAZ32"|"0001000004"|"AB01"|"USD"|"20230118"|"A1"|"S1"|"F"|"XX"|""|"00"|"05"