When I tried to replicate the issue in my environment, with below code:
linked_service_name = "SqlServer1"
df = spark.read \
.format("jdbc") \
.option("url", f"jdbc:sqlserver://;{linked_service_name}") \
.option("dbtable", "dbo.student") \
.load()
df.show()
I got the same error:
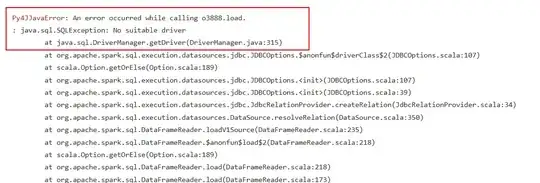
I added driver to the code as mentioned below:
jdbcDriver = "com.microsoft.sqlserver.jdbc.SQLServerDriver"
linked_service_name = "SqlServer1"
df = spark.read \
.format("jdbc") \
.option("driver", jdbcDriver)\
.option("url", f"jdbc:sqlserver://;{linked_service_name}") \
.option("dbtable", "dbo.student") \
.load()
df.show()
I got below error:

As per this Jdbc URl should be in below format:
jdbc:sqlserver://[serverName[\instanceName][:portNumber]][;property=value[;property=value]]
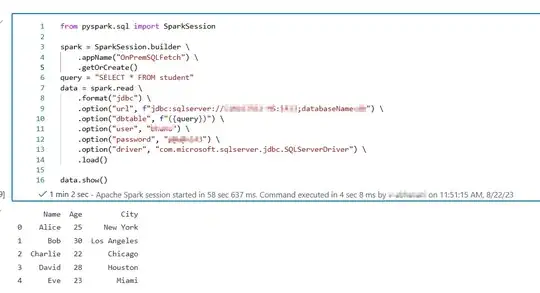
So, I connected to SQL server with above jdbc URL format with below code:
from pyspark.sql import SparkSession
spark = SparkSession.builder \
.appName("OnPremSQLFetch") \
.getOrCreate()
query = "SELECT * FROM student"
data = spark.read \
.format("jdbc") \
.option("url", f"jdbc:sqlserver://<serverName>:1433;databaseName=<dbName>") \
.option("dbtable", f"({query})") \
.option("user", "<userName>") \
.option("password", "<password>") \
.option("driver", "com.microsoft.sqlserver.jdbc.SQLServerDriver") \
.load()
data.show()
It connected to on-premises sql server successfully.
If the on-premises data source is not publicly accessible, then copy the data from on-premises to Azure SQL database using this and retrieve data from Azure SQL database with mentioned code.
As per this it is not possible to connect on-premises sql server directly in synapse notebook. You can follow above procedures.
 Actually my server name is AKHAYASQL/SQL2019 and its in my local machine i am trying to connect it using self hosted IR
Actually my server name is AKHAYASQL/SQL2019 and its in my local machine i am trying to connect it using self hosted IR