The options for 2D plots of (x,y,z) in R are a bit numerous. However, grappling with the options is a bit of a challenge, especially in the case that all three are continuous.
To clarify the problem (and possibly assist in explaining why I might be getting tripped up with contour or image), here is a possible classification scheme:
- Case 1: The value of z is not provided but is a conditional density based on values in (x,y). (Note: this is essentially relegating the calculation of z to a separate function - a density estimation. Something still has to use the output of that calculation, so allowing for arbitrary calculations would be nice.)
- Case 2: (x,y) pairs are unique and regularly spaced. This implies that only one value of z is provided per (x,y) value.
- Case 3: (x,y) pairs are unique, but are continuous. Coloring or shading is still determined by only 1 unique z value.
- Case 4: (x,y) pairs are not unique, but are regularly spaced. Coloring or shading is determined by an aggregation function on the z values.
- Case 5: (x,y) pairs are not unique, are continuous. Coloring / shading must be determined by an aggregation function on the z values.
If I am missing some cases, please let me know. The case that interests me is #5. Some notes on relationships:
- Case #1 seems to be well supported already.
- Case #2 is easily supported by
heatmap,image, and functions inggplot. - Case #3 is supported by base
plot, though use of a color gradient is left to the user. - Case #4 can become case #2 by use of a split & apply functionality. I have done that before.
- Case #5 can be converted to #4 (and then #2) by using
cut, but this is inelegant and boxy. Hex binning may be better, though that does not seem to be easily conditioned on whether there is a steep gradient in the value of z. I'd settle for hex binning, but alternative aggregation functions are quite welcome, especially if they can utilize the z values.
How can I do #5? Here is code to produce a saddle, though the value of spread changes the spread of the z value, which should create differences in plotting gradients.
N = 1000
spread = 0.6 # Vals: 0.6, 3.0
set.seed(0)
rot = matrix(rnorm(4), ncol = 2)
mat0 = matrix(rnorm(2 * N), ncol = 2)
mat1 = mat0 %*% rot
zMean = mat0[,2]^2 - mat0[,1]^2
z = rnorm(N, mean = zMean, sd = spread * median(abs(zMean)))
I'd like to do something like hexbin, but I've banged on this with ggplot and haven't made much progress. If I can apply an arbitrary aggregation function to the z values in a region, that would be even better. (The form of such a function might be like plot(mat1, colorGradient = f(z), aggregation = "bin", bins = 50).)
How can I do this in ggplot or another package? I am happy to make this question a community wiki question (or other users can, by editing it enough times). If so, one answer per post, please, so that we can focus on, say, ggplot, levelplot, lattice, contourplot (or image), and other options, if they exist.
Updates 1: The volcano example is a good example of case #3: the data is regularly spaced (it could be lat/long), with one z value per observation. A topographic map has (latitude, longitude, altitude), and thus one value per location. Suppose one is obtaining weather (e.g. rainfall, windspeed, sunlight) over many days for many randomly placed sensors: that is more akin to #5 than to #3 - we may have lat & long, but the z values can range quite a bit, even for the same or nearby (x,y) values.
Update 2: The answers so far, by DWin, Kohske, and John Colby are all excellent. My actual data set is a small sample of a larger set, but at 200K points it produces interesting results. On the (x,y) plane, it is has very high density in some regions (thus, overplotting would occur in those areas) and much lower density or complete absence in other regions. With John's suggestion via fields, I needed to subsample the data for Tps to work out (I'll investigate if I can do it without subsampling), but the results are quite interesting. Trying rms/Hmisc (DWin's suggestion), the full 200K points seem to work out well. Kohske's suggestion is quite good, and, as the data is transformed into a grid before plotting, there's no issue with the number of input data points. It also gives me greater flexibility to determine how to aggregate the z values in the region. I am not yet sure if I will use mean, median, or some other aggregation.
I also intend to try out Kohske's nice example of mutate + ddply with the other methods - it is a good example of how to get different statistics calculated over a given region.
Update 3: The different methods are distinct and several are remarkable, though there isn't a clear winner. I selected John Colby's answer as the first. I think I will use that or DWin's method in further work.
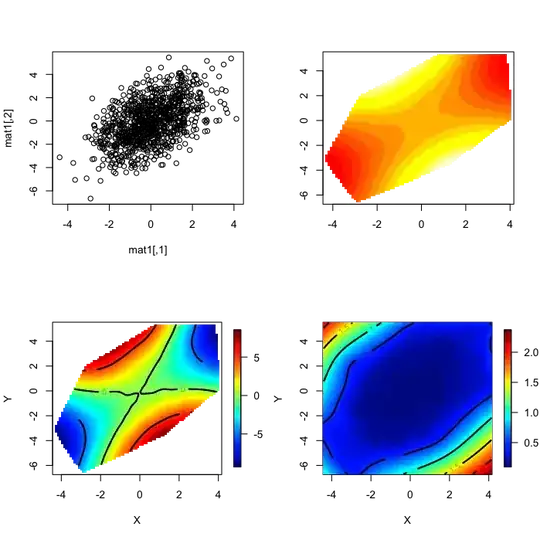
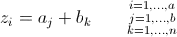 The plotting paradigm is lattice and you can also get contour plots as well as this pretty levelplot. If you want the predicted values at an iterior point, then you can get that with the
The plotting paradigm is lattice and you can also get contour plots as well as this pretty levelplot. If you want the predicted values at an iterior point, then you can get that with the