I want to find 2nd, 3rd, ... nth maximum value of a column.
Asked
Active
Viewed 1.2e+01k times
33
-
1too generic I think: specify at least on which DBMS... – ila Sep 17 '08 at 07:14
-
1What database? I don't think there is a very good "generic" solution to this problem. – Matthew Watson Sep 17 '08 at 07:12
28 Answers
42
Consider the following Employee table with a single column for salary.
+------+ | Sal | +------+ | 3500 | | 2500 | | 2500 | | 5500 | | 7500 | +------+
The following query will return the Nth Maximum element.
select SAL from EMPLOYEE E1 where
(N - 1) = (select count(distinct(SAL))
from EMPLOYEE E2
where E2.SAL > E1.SAL )
For eg. when the second maximum value is required,
select SAL from EMPLOYEE E1 where
(2 - 1) = (select count(distinct(SAL))
from EMPLOYEE E2
where E2.SAL > E1.SAL )
+------+ | Sal | +------+ | 5500 | +------+
dexter
- 13,365
- 5
- 39
- 56
-
2
-
Great answer! I have faced this problem before and was troubled about how to solve it without being specific to a vendor :) One possible drawback is that it does a subquery for each row. – gaboroncancio Mar 20 '15 at 16:36
-
This is awesome! I am using it with `>=` operator to get all the rows with up to Nth position. I would like to add a ranking to it, like '1' for the max value, '2' for the second max, etc.. Do you have any idea how to go about it. – NurShomik Oct 21 '16 at 14:25
-
1@NurShomik if you need a generic function for rank, see this: http://stackoverflow.com/a/3333697/1385252 – dexter Oct 22 '16 at 08:28
-
2please explain. I am not being able to understand, how Comparison is helping us out. – Usman May 17 '18 at 06:51
-
1it was great , but would be better if you could please provide an explanation how it executes – Achy97 Jun 12 '19 at 08:37
-
How do you deal with subquery returns more than 1 row for N = 4? – Elliott de Launay Apr 09 '20 at 01:09
-
Modifying it to `Select DISTINCT SAL from EMPLOYEE E1 where` .... worked – Elliott de Launay Apr 09 '20 at 02:23
-
way more sophisticated and versatile than other answers. Fiddle link: http://sqlfiddle.com/#!9/6a58ad/7 – Pawan Tiwari Dec 21 '22 at 07:11
15
You didn't specify which database, on MySQL you can do
SELECT column FROM table ORDER BY column DESC LIMIT 7,10;
Would skip the first 7, and then get you the next ten highest.
Pieter
- 17,435
- 8
- 50
- 89
-
If you are using mysql, this wont work in oracle (or mssql I believe) – Matthew Watson Sep 17 '08 at 07:16
12
You could sort the column into descending format and then just obtain the value from the nth row.
EDIT::
Updated as per comment request. WARNING completely untested!
SELECT DOB FROM (SELECT DOB FROM USERS ORDER BY DOB DESC) WHERE ROWID = 6
Something like the above should work for Oracle ... you might have to get the syntax right first!
TK.
- 46,577
- 46
- 119
- 147
-
Can you please provide a code snippet? I tried your suggestion but I was unable to obtain value from the nth row. – Sep 19 '11 at 10:21
-
1Using `ROWID` is neither a safe nor a practical thing to do. Take the case of [tag:sqlite]. `ROWID` may or may not be generated serially. Moreover the order of `ROWID` might not match with that of the requested column. – Quirk Apr 15 '16 at 19:12
-
This will be slow as it requires ordering the whole table first before then selecting the nth row. Some databases now provide this functionality see answers below from Pieter and Steven Dickinson, for example. – kentsurrey May 29 '20 at 16:04
9
Again you may need to fix for your database, but if you want the top 2nd value in a dataset that potentially has the value duplicated, you'll want to do a group as well:
SELECT column
FROM table
WHERE column IS NOT NULL
GROUP BY column
ORDER BY column DESC
LIMIT 5 OFFSET 2;
Would skip the first two, and then will get you the next five highest.
SemperFi
- 2,358
- 6
- 31
- 51
5
Pure SQL (note: I would recommend using SQL features specific to your DBMS since it will be likely more efficient). This will get you the n+1th largest value (to get smallest, flip the <). If you have duplicates, make it COUNT( DISTINCT VALUE )..
select id from table order by id desc limit 4 ;
+------+
| id |
+------+
| 2211 |
| 2210 |
| 2209 |
| 2208 |
+------+
SELECT yourvalue
FROM yourtable t1
WHERE EXISTS( SELECT COUNT(*)
FROM yourtable t2
WHERE t1.id <> t2.id
AND t1.yourvalue < t2.yourvalue
HAVING COUNT(*) = 3 )
+------+
| id |
+------+
| 2208 |
+------+
Matt Rogish
- 24,435
- 11
- 76
- 92
3
(Table Name=Student, Column Name= mark)
select * from(select row_number() over (order by mark desc) as t,mark from student group by mark) as td where t=4
Andro Selva
- 53,910
- 52
- 193
- 240
German Alex
- 31
- 1
-
MS SQL Server [row_number](https://msdn.microsoft.com/en-us/library/ms186734.aspx) – woodvi Jul 13 '15 at 19:55
2
You can find the nth largest value of column by using the following query:
SELECT * FROM TableName a WHERE
n = (SELECT count(DISTINCT(b.ColumnName))
FROM TableName b WHERE a.ColumnName <=b.ColumnName);
Abhishek B Patel
- 887
- 10
- 13
2
select column_name from table_name
order by column_name desc limit n-1,1;
where n = 1, 2, 3,....nth max value.
Eray Balkanli
- 7,752
- 11
- 48
- 82
rashedcs
- 3,588
- 2
- 39
- 40
1
This is query for getting nth Highest from colomn put n=0 for second highest and n= 1 for 3rd highest and so on...
SELECT * FROM TableName
WHERE ColomnName<(select max(ColomnName) from TableName)-n order by ColomnName desc limit 1;
Prashant Maheshwari Andro
- 1,686
- 14
- 12
1
Simple SQL Query to get the employee detail who has Nth MAX Salary in the table Employee.
sql> select * from Employee order by salary desc LIMIT 1 OFFSET <N - 1>;
Consider table structure as:
Employee ( id [int primary key auto_increment], name [varchar(30)], salary [int] );
Example:
If you need 3rd MAX salary in the above table then, query will be:
sql> select * from Employee order by salary desc LIMIT 1 OFFSET 2;
Similarly:
If you need 8th MAX salary in the above table then, query will be:
sql> select * from Employee order by salary desc LIMIT 1 OFFSET 7;
NOTE: When you have to get the Nth
MAXvalue you should give theOFFSETas (N - 1).
Like this you can do same kind of operation in case of salary in ascending order.
Rahul Raina
- 3,322
- 25
- 30
1
mysql query: suppose i want to find out nth max salary form employee table
select salary
form employee
order by salary desc
limit n-1,1 ;
mjp
- 131
- 4
1
Just dug out this question when looking for the answer myself, and this seems to work for SQL Server 2005 (derived from Blorgbeard's solution):
SELECT MIN(q.col1) FROM (
SELECT
DISTINCT TOP n col1
FROM myTable
ORDER BY col1 DESC
) q;
Effectively, that is a SELECT MIN(q.someCol) FROM someTable q, with the top n of the table retrieved by the SELECT DISTINCT... query.
1
Here's a method for Oracle. This example gets the 9th highest value. Simply replace the 9 with a bind variable containing the position you are looking for.
select created from (
select created from (
select created from user_objects
order by created desc
)
where rownum <= 9
order by created asc
)
where rownum = 1
If you wanted the nth unique value, you would add DISTINCT on the innermost query block.
Dave Costa
- 47,262
- 8
- 56
- 72
0
Answer : top second:
select * from (select * from deletetable where rownum <=2 order by rownum desc) where rownum <=1
-
1When you don't add something new, please don't answer 4 year old questions :) – fancyPants Sep 25 '12 at 08:43
0
(TableName=Student, ColumnName=Mark) :
select *
from student
where mark=(select mark
from(select row_number() over (order by mark desc) as t,
mark
from student group by mark) as td
where t=2)
C B
- 1,677
- 6
- 18
- 20
German Alex
- 31
- 1
0
I think that the query below will work just perfect on oracle sql...I have tested it myself..
Info related to this query : this query is using two tables named employee and department with columns in employee named: name (employee name), dept_id (common to employee and department), salary
And columns in department table: dept_id (common for employee table as well), dept_name
SELECT
tab.dept_name,MIN(tab.salary) AS Second_Max_Sal FROM (
SELECT e.name, e.salary, d.dept_name, dense_rank() over (partition BY d.dept_name ORDER BY e.salary) AS rank FROM department d JOIN employee e USING (dept_id) ) tab
WHERE
rank BETWEEN 1 AND 2
GROUP BY
tab.dept_name
thanks
Mangiucugna
- 1,732
- 1
- 14
- 23
ria
- 1
- 1
0
Select min(fee)
from fl_FLFee
where fee in (Select top 4 Fee from fl_FLFee order by 1 desc)
Change Number four with N.
slavoo
- 5,798
- 64
- 37
- 39
0
You can simplify like this
SELECT MIN(Sal) FROM TableName
WHERE Sal IN
(SELECT TOP 4 Sal FROM TableName ORDER BY Sal DESC)
If the Sal contains duplicate values then use this
SELECT MIN(Sal) FROM TableName
WHERE Sal IN
(SELECT distinct TOP 4 Sal FROM TableName ORDER BY Sal DESC)
the 4 will be nth value it may any highest value such as 5 or 6 etc.
Qantas 94 Heavy
- 15,750
- 31
- 68
- 83
0
MySQL:
select distinct(salary) from employee order by salary desc limit (n-1), 1;
stealthyninja
- 10,343
- 11
- 51
- 59
Ritesh
- 1
- 4
0
In PostgreSQL, to find N-th largest salary from Employee table.
SELECT * FROM Employee WHERE salary in
(SELECT salary FROM Employee ORDER BY salary DESC LIMIT N)
ORDER BY salary ASC LIMIT 1;
Trung Lê Hoàng
- 35
- 1
- 8
0
Solution to find Nth Maximum value of a particular column in SQL Server:
Employee table:
Sales table:
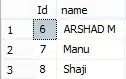
Employee table data:
==========
Id name
=========
6 ARSHAD M
7 Manu
8 Shaji
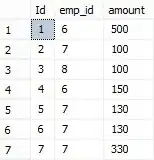
Sales table data:
=================
id emp_id amount
=================
1 6 500
2 7 100
3 8 100
4 6 150
5 7 130
6 7 130
7 7 330
Query to Find out details of an employee who have highest sale/ Nth highest salesperson
select * from (select E.Id,E.name,SUM(S.amount) AS 'total_amount' from employee E INNER JOIN Sale S on E.Id=S.emp_id group by S.emp_id,E.Id,E.name ) AS T1 WHERE(0)=( select COUNT(DISTINCT(total_amount)) from(select E.Id,E.name,SUM(S.amount) AS 'total_amount' from employee E INNER JOIN Sale S on E.Id=S.emp_id group by S.emp_id,E.Id,E.name )AS T2 WHERE(T1.total_amount<T2.total_amount) );
In the WHERE(0) replace 0 by n-1
Result:
========================
id name total_amount
========================
7 Manu 690
ARSHAD M
- 21
- 3
0
In SQL Server, just do:
select distinct top n+1 column from table order by column desc
And then throw away the first value, if you don't need it.
Blorgbeard
- 101,031
- 48
- 228
- 272
0
select sal,ename from emp e where
2=(select count(distinct sal) from emp where e.sal<=emp.sal) or
3=(select count(distinct sal) from emp where e.sal<=emp.sal) or
4=(select count(distinct sal) from emp where e.sal<=emp.sal) order by sal desc;
Taryn
- 242,637
- 56
- 362
- 405
0
for SQL 2005:
SELECT col1 from
(select col1, dense_rank(col1) over (order by col1 desc) ranking
from t1) subq where ranking between 2 and @n
0
Another one for Oracle using analytic functions:
select distinct col1 --distinct is required to remove matching value of column
from
( select col1, dense_rank() over (order by col1 desc) rnk
from tbl
)
where rnk = :b1
Community
- 1
- 1
-1
Table employee
salary
1256
1256
2563
8546
5645
You find the second max value by this query
select salary
from employee
where salary=(select max(salary)
from employee
where salary <(select max(salary) from employee));
You find the third max value by this query
select salary
from employee
where salary=(select max(salary)
from employee
where salary <(select max(salary)
from employee
where salary <(select max(salary)from employee)));
RichardTheKiwi
- 105,798
- 26
- 196
- 262
Raman kumar
- 1
- 1
-
The outermost selects are extraneous. Stopping at the first max(salary) would have worked. – RichardTheKiwi Sep 29 '12 at 11:44
-