As Tessmore said - you can't. But you can make it work by using Google Scholar Organic Results API from SerpApi that bypasses quota limits and blocks from search engines so you don't have to think about how to reduce the chance of being blocked.
Example:
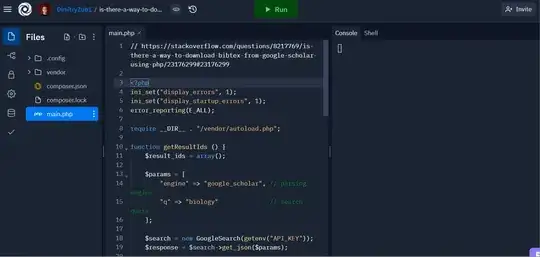
Install google-search-results-php package first via composer:
$ composer require serpapi/google-search-results-php:2.0
Code to integrate and full example in the online IDE:
<?php
ini_set("display_errors", 1);
ini_set("display_startup_errors", 1);
error_reporting(E_ALL);
require __DIR__ . "/vendor/autoload.php";
function getResultIds () {
$result_ids = array();
$params = [
"engine" => "google_scholar", // parsing engine
"q" => "biology" // search query
];
$search = new GoogleSearch(getenv("API_KEY"));
$response = $search->get_json($params);
foreach ($response->organic_results as $result) {
// print_r($result->result_id);
array_push($result_ids, $result->result_id);
}
return $result_ids;
}
function getBibtexData () {
$bibtex_data = array();
foreach (getResultIds() as $result_id) {
$params = [
"engine" => "google_scholar_cite", // parsing engine
"q" => $result_id
];
$search = new GoogleSearch(getenv("API_KEY"));
$response = $search->get_json($params);
foreach ($response->links as $result) {
if ($result->name === "BibTeX") {
array_push($bibtex_data, $result->link);
}
}
}
return $bibtex_data;
}
print_r(json_encode(getBibtexData(), JSON_PRETTY_PRINT | JSON_UNESCAPED_SLASHES));
?>
Output:
[
"https://scholar.googleusercontent.com/scholar.bib?q=info:KNJ0p4CbwgoJ:scholar.google.com/&output=citation&scisdr=CgXjqB_WGAA:AAGBfm0AAAAAYkm8amenawYn_EBidiCQT5QBh0L1KJEX&scisig=AAGBfm0AAAAAYkm8at9X4P3eIWKUCOc6UriCEDKVsQE0&scisf=4&ct=citation&cd=-1&hl=en",
"https://scholar.googleusercontent.com/scholar.bib?q=info:6zRLFbcxtREJ:scholar.google.com/&output=citation&scisdr=CgWhqfi6GAA:AAGBfm0AAAAAYkm8bDoIhTlfTkQFCOzYGax54Bst576o&scisig=AAGBfm0AAAAAYkm8bMe_7Nq4e4pB5lg_eR9jmeGrO8ek&scisf=4&ct=citation&cd=-1&hl=en",
"https://scholar.googleusercontent.com/scholar.bib?q=info:6Yb0qOX88FMJ:scholar.google.com/&output=citation&scisdr=CgXn_4MdGAA:AAGBfm0AAAAAYkm8bi8ypCZcFDNEQZYZeoSlvx-U1OSk&scisig=AAGBfm0AAAAAYkm8bnFMnwTWGfkfJDCNEx0C4n-aQwql&scisf=4&ct=citation&cd=-1&hl=en",
"https://scholar.googleusercontent.com/scholar.bib?q=info:HFdEElNr3IgJ:scholar.google.com/&output=citation&scisdr=CgXKCFpQGAA:AAGBfm0AAAAAYkm8byukcQCl4WHQx-nSNp2pC1gUFSKG&scisig=AAGBfm0AAAAAYkm8b8EReTVkLwtxfth_pjwMyyY3dqts&scisf=4&ct=citation&cd=-1&hl=en",
"https://scholar.googleusercontent.com/scholar.bib?q=info:bs-D_MeC14YJ:scholar.google.com/&output=citation&scisdr=CgXEUXwWGAA:AAGBfm0AAAAAYkm8bwwfMNJrffe16EaGypsem9JlmGTi&scisig=AAGBfm0AAAAAYkm8b6nWlPOQL63fXg6dV2U-JQbpyQyS&scisf=4&ct=citation&cd=-1&hl=en",
"https://scholar.googleusercontent.com/scholar.bib?q=info:Rn1qFVLRfKwJ:scholar.google.com/&output=citation&scisdr=CgU-HswkGAA:AAGBfm0AAAAAYkm8cHE1YRK23eHV8nzF89Eem-Bsuz72&scisig=AAGBfm0AAAAAYkm8cDEj8ZrzZjAo2bNX-tjYYYJYQZay&scisf=4&ct=citation&cd=-1&hl=en",
"https://scholar.googleusercontent.com/scholar.bib?q=info:d8thHtTwq6YJ:scholar.google.com/&output=citation&scisdr=CgXj7oe9GAA:AAGBfm0AAAAAYkm8cTYamCKGKImjdg5MQdgbxUIIHAEY&scisig=AAGBfm0AAAAAYkm8cTcop1ceKzKYvKAKtvlSQ1EdEtSN&scisf=4&ct=citation&cd=-1&hl=en",
"https://scholar.googleusercontent.com/scholar.bib?q=info:IUmhOhGaDaEJ:scholar.google.com/&output=citation&scisdr=CgU0qZ2_GAA:AAGBfm0AAAAAYkm8ctCPwoihZkjbNcdEqSnwa0J3jwDy&scisig=AAGBfm0AAAAAYkm8cingBcYnEp8YRqFDFdN-FAEBgDT7&scisf=4&ct=citation&cd=-1&hl=en",
"https://scholar.googleusercontent.com/scholar.bib?q=info:PWsf8O5OMQEJ:scholar.google.com/&output=citation&scisdr=CgVBAJxXGAA:AAGBfm0AAAAAYkm8c3CDKQG0Wh_lWsXU_DZxEJkwZz5y&scisig=AAGBfm0AAAAAYkm8c6I-HjAxD1Gy6FLFDRdxH_qU4OBr&scisf=4&ct=citation&cd=-1&hl=en",
"https://scholar.googleusercontent.com/scholar.bib?q=info:yGvgHH8ROuIJ:scholar.google.com/&output=citation&scisdr=CgXFuhOkGAA:AAGBfm0AAAAAYkm8dD0rcSR4LQF8GgTxx865BADtXNDN&scisig=AAGBfm0AAAAAYkm8dIQhodz3rHF9IUdaCSRlhdudACNQ&scisf=4&ct=citation&cd=-1&hl=en"
]
Bibtex data from the first URL:
@article{woese2004new,
title={A new biology for a new century},
author={Woese, Carl R},
journal={Microbiology and molecular biology reviews},
volume={68},
number={2},
pages={173--186},
year={2004},
publisher={Am Soc Microbiol}
}
Disclaimer, I work for SerpApi.