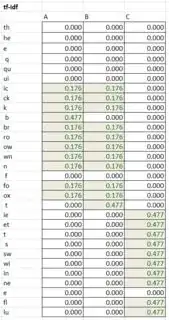
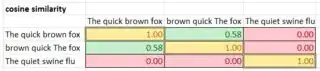
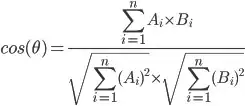I've had some success comparing strings using the PHP levenshtein function.
However, for two strings which contain substrings that have swapped positions, the algorithm counts those as whole new substrings.
For example:
levenshtein("The quick brown fox", "brown quick The fox"); // 10 differences
are treated as having less in common than:
levenshtein("The quick brown fox", "The quiet swine flu"); // 9 differences
I'd prefer an algorithm which saw that the first two were more similar.
How could I go about coming up with a comparison function that can identify substrings which have switched position as being distinct to edits?
One possible approach I've thought of is to put all the words in the string into alphabetical order, before the comparison. That takes the original order of the words completely out of the comparison. A downside to this, however, is that changing just the first letter of a word can create a much bigger disruption than a changing a single letter should cause.
What I'm trying to achieve is to compare two facts about people which are free text strings, and decide how likely these facts are to indicate the same fact. The facts might be the school someone attended, the name of their employer or publisher, for example. Two records may have the same school spelled differently, words in a different order, extra words, etc, so the matching has to be somewhat fuzzy if we are to make a good guess that they refer to the same school. So-far it is working very well for spelling errors (I am using a phoenetic algorithm similar to metaphone on top of this all) but very poorly if you switch the order of words around which seem common in a school: "xxx college" vs "college of xxx".