I have implemented a suffix tree in Python to make full-text-searchs, and it's working really well. But there's a problem: the indexed text can be very big, so we won't be able to have the whole structure in RAM.
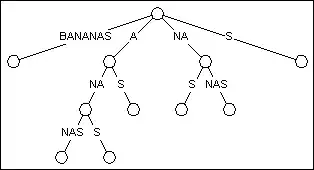
IMAGE: Suffix tree for the word BANANAS (in my scenario, imagine a tree 100000 times bigger).
So, researching a little bit about it I found the pickle module, a great Python module for "loading" and "dumping" objects from/into files, and guess what? It works wonderfully with my data structure.
So, making the long story shorter: What would be the best strategy to store and retrieve this structure on/from disk? I mean, a solution could be to store each node in a file and load it from disk whenever is needed, but this isn't the best think to do (too many disk accesses).
Footnote: Although I have tagged this question as python, the programming language isn't the important part of the question, the disk storing/retrieving strategy is really the main point.