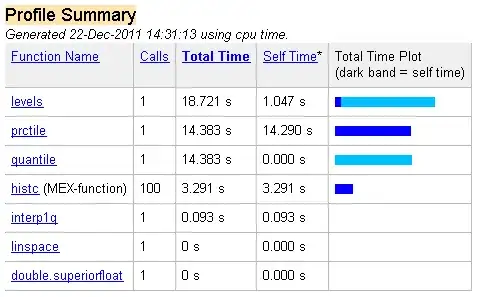
I have a MATLAB routine with one rather obvious bottleneck. I've profiled the function, with the result that 2/3 of the computing time is used in the function levels:
The function levels takes a matrix of floats and splits each column into nLevels buckets, returning a matrix of the same size as the input, with each entry replaced by the number of the bucket it falls into.
To do this I use the quantile function to get the bucket limits, and a loop to assign the entries to buckets. Here's my implementation:
function [Y q] = levels(X,nLevels)
% "Assign each of the elements of X to an integer-valued level"
p = linspace(0, 1.0, nLevels+1);
q = quantile(X,p);
if isvector(q)
q=transpose(q);
end
Y = zeros(size(X));
for i = 1:nLevels
% "The variables g and l indicate the entries that are respectively greater than
% or less than the relevant bucket limits. The line Y(g & l) = i is assigning the
% value i to any element that falls in this bucket."
if i ~= nLevels % "The default; doesnt include upper bound"
g = bsxfun(@ge,X,q(i,:));
l = bsxfun(@lt,X,q(i+1,:));
else % "For the final level we include the upper bound"
g = bsxfun(@ge,X,q(i,:));
l = bsxfun(@le,X,q(i+1,:));
end
Y(g & l) = i;
end
Is there anything I can do to speed this up? Can the code be vectorized?